12. readを作る
ところで、この時点(出力関数を作成した時点)で実はREPLそのものは成立する。
現時点、ゲームの終了条件、ってのは定義してないが、単純に言うと、Python原作のページでも書かれてるが、world構造体の2つのidが一致した時、ゲームが終わる、と言うことだ。
と言うのも2つのidが一致する => 残ったプレイヤーが一人のみ => 結果、彼/彼女がババ(ジョーカー)を持っている、と言う事だからだ。
これを使ってババ抜きの終了判定関数を書くと次のようになる。
;;; ゲーム終了判定
(define (game-ends? w)
(let ((id1 (world-id1 w)) (id2 (world-id2 w)))
(= id1 id2)))
そしてworld構造体の初期値を考えなければならない。
再録も兼ねるが、各スロット(合計7つ)は次のような事を意図している。
- card: player1が引いたカード。出力用。書き換え前提だし、初期値は無いので#fでも与えておけば良い。
- clist: 循環リストの保存先。(make-clist n)を設定しておく。n(つまりプレイ人数)は外部から与えられる。
- discarded: player1が捨てたカード。出力用。書き換え前提だし、初期値はないので空リストを与えておく。
- dpair: 今回のid1、id2の値。まだworld構造体が更新されてないので初期値はない。書き換え前提。出力用。空リストを与えておく。
- id1: 最初のplayer1の位置。初期値は0番目、と言う事で0になる。
- id2: 最初のplayer2の位置。初期値は1番目、と言う事で1になる。
- players: ゲームに参加してるプレイヤーを意図してて、実際はカードのリストのリストになる。(dealCards (shuffle-list (make-deck) 1) n)で生成する。1はシャッフル回数なんで好きな数を与えて良い。また、nは参加人数で、これも外部から与えられる。
そうすると、REPLはまずは次のようになるわけだ。
;;; REPL 第1版
(define (oldmaid n)
(let loop ((w (world #f (make-clist n) '() '() 0 1
(dealCards (shuffle-list (make-deck) 1) n))))
(if (game-ends? w)
'done
;;; Read-Eval-Print loop(loop (print (world-go (read) w))))))
一応動作テストとしては問題なく動くのが確認できるだろう。
;;; 例えば4人でプレイする状況を演出するには次のようなコマンドをプロンプトに入力する。> (oldmaid 4)

いきなり入力が始まってビックリするだろうが。ゲームが終わった時、単純にdoneしか表示されないが。
動くことは動く。動作テストとしては充分なのだ。
しかし、気づくだろうが、一番の問題はそこじゃない、のだ。
その前に。
末尾再帰状態になってるloopは当然world構造体を受け取るのが前提である。
しかし、そこには出力関数が被ってる。どうして副作用目的の関数をツッコんでるのに問題なく動作するんだ?と思う向きもあるだろうが、それが前回行った、副作用目的のprintの返り値を、敢えてprintが仮引数として受け取ったworld構造体そのものにした、と言う効果なのだ。
つまり、このprintの真の作用はworld-goが手渡してくるworld構造体をそのまま「右から左へと受け流してる」事なのである。

今回作ったprint関数は「ついでに」印字してるだけ、なのだ。まさしく印字が副作用、になってるわけだ。
本題に戻ろう。
テストを実行してみると、ちとおかしな事に気づくだろう。
「あれ、どのプレイヤーも実は俺がやってね?」
そう、実は現時点、まったくプレイにコンピュータは関与してない。
例えば4人でプレイする状況を設定したとしてもプレイヤー0、プレイヤー1、プレイヤー2、プレイヤー3とも貴方がコントロールしてる事になる。
動作テストとしてはそれでもいいが、ゲームとしてはダメダメ、である。
最初のプレイヤー以外はコンピュータが操作すべきなのである。
とは言ってもやっぱ動作テストが性交成功するのは嬉しいもんだろ。
確かに
READ->EVAL->PRINT->READ->EVAL->......->EVAL->PRINT->......
と言う動作モデルは成立してるのだ。
そしてこのモデルが推移してる間に
プレイヤー0 -> プレイヤー1 -> プレイヤー2 -> プレイヤー3 -> プレイヤー0 -> ...... -> プレイヤー2 -> プレイヤー3 -> プレイヤー0 -> ....
と言うルーピングも(誰かがあがらない限り)確認出来る。
問題は、だ。
最初のプレイヤーを除き、他のプレイヤーをコンピュータが演じる際に、どうやって入力を人からプログラムが奪うのか、と言う事だ。
言い換えると、この問題は入力関数に素のreadを使ったから生じた問題、である。
つまり、ここで自作すべき入力関数は条件が揃った場合、キーボードからの入力じゃない入力をコンピュータ側が「勝手に生成する」ような関数である。
そしてその条件は、world構造体のplayersスロットの先頭リストが人がプレイする前提だとすると、world構造体のid1が0以外、と言う事である。
- world構造体のid1が0 -> 人がキーボードから入力する
- world構造体のid1が0以外 -> プログラムが勝手に入力を生成する
この条件を活かした入力機構を定義すると次のようになる。
;;; read
(define (input w)
(let ((id1 (world-id1 w))
(id2 (world-id2 w))
(players (world-players w)))
(let ((k (length (list-ref players id2))))
(cond ((zero? id1)
(display
(format (cdr (assq 'inputSelectCard *messages*))
(- k 1)))
(read))
(else (selectCard k))))))
関数inputで利用するworld構造体のスロットはid1、id2、playersの3つだ。
id1は当然、現在のプレイヤーが人なのかコンピュータであるべきか、を判別するために必要だ。id1が0の時は人、id1が0以外の時はコンピュータがプレイする前提になる、ってのは既に言った通りだ。
id2は「カードを引かれるプレイヤー」を算出する為に使われる。そしてid2を使ってplayersリストから該当するプレイヤー(実際はカードのリスト)を引っ張ってくるわけだ。
なんでid2とplayersが必要なんだろう。一つは人が入力する際のプロンプトを生成するため、である。
何枚目のカードを引きますか? (0 〜 4)
そう、これ(このケースだと4)を生成する為、「カードを引かれる側」の情報が必要なのである。
もう一つは乱数でコンピュータ側にカードを引かせる為、である。
以前作ったコンピュータ用の「カードを引く」関数、selectCardと言うものがあった。
再録しよう。
;;; num枚のカードから引くカードを決める
(define selectCard random)
つまり、そこに「カードを引かれる側が持ってるカードの枚数」の情報をハメ込むのである。
これにより
- id1が0の時 -> プロンプトを表示し、プレイヤー(人)に入力を促す
- id1が0以外の時 -> 乱数生成により勝手にコンピュータがカードを引く
と言う機構がでっち上げられるわけだ。
早速テストしてみよう。
REPLを次のように改造する。
;;; REPL 第2版
(define (oldmaid n)
(let loop ((w (world #f (make-clist n) '() '() 0 1
(dealCards (shuffle-list (make-deck) 1) n))))
(if (game-ends? w)
'done
;;; Read-Eval-Print loop
(loop (print (world-go (input w) w))))))
再び、Racketのリスナーで(oldmaid4)を実行すると、今度はプレイヤー0以外は「勝手にコンピュータがゲームを進める」ようになってるのが分かるだろう。

これでコンピュータがババ抜きをプレイする機構を作り上げる事が出来た(※1)。
また、ゲームが終了した時に'doneを表示するだけ、だったのだけど、負けたプレイヤーを表示するように改変しよう。
これには以前作ったshowResult関数を利用する。
;;; REPL 第3版
(define (oldmaid n)
(let loop ((w (world #f (make-clist n) '() '() 0 1
(dealCards (shuffle-list (make-deck) 1) n))))
(if (game-ends? w)
(display (showResult (world-id1 w)))
;;; Read-Eval-Print loop
(loop (print (world-go (input w) w))))))
こうすると最下位だったヤローがババ抜きの最後に表示されるようになる。

さて、この時点で殆ど「ババ抜きプログラム」は完成してる。
現時点で完成度95%ってトコなんじゃないか。
ゲームもプレイ出来るし進行には全く問題が見られない。
次は本体以外のところにちょっと手を入れてみよう。
まずは初期化の問題である。
13. 初期化機構を作る
現時点、ババ抜きプログラム、oldmaidを起動するといきなり入力を促される。
そして一巡目では手持ちのカードが重複だらけで、その回で大量にカードが捨てられるわけだ。
この「カードを大量に捨てる」行為をそもそもゲーム開始前に終わらせておきたい。
そこで、カードを配り、カードを捨て、構造体の初期値を設定する行為を「初期化」プロセスと言う事にしよう。
そして、ゲームがはじまる(入力を促される)前に全ての初期化作業を終わらせておこう。
なお、初期化プロセスは一般的に言って、REPLとは全く別のプログラムだと考えて良い。
と言うか、初期化、と言うプログラムが終了した状態で何らかの情報をREPLに渡し、REPLがスタートするようになっている。
言い換えると初期化用プログラムはREPLに結果を手渡す為だけに存在する、独立した一種のスクリプトである。
ちなみに、ソフトウェアによってはCLIで起動した時、何らかのグラフィック的なブツを表示する事がある。
これも初期化プロセスの一種で、「☓☓と言うソフトウェアですよ」と言う主張を只してるように見えるが、実際には、これを表示する時点でソフトウェアがいろいろと入力に向けての準備をしていたりするもの、である。

ANSI Common Lisp処理系であるCLISPの起動画面の例。「CLISP」と言うタイトル、ヴァージョン番号と著作権、そしてヘルプ参照方法を表示してるだけ、に見えるが、裏ではANSI Common Lisp標準関数やらCLISP独自の関数等をロードしてユーザー入力に対して準備をしてたりする。
さて、Python原作を見てみると、初期化は次のように行えば良いらしい。

Python原作。入力が行われる前に、このような情報が開示される。
- 各プレイヤーにカードを配り、カードを表示する。
- 各プレイヤーはペアが成立してるカードを捨て、捨てられたカードを表示する。
- 現時点の各プレイヤーのカードの状態を表示する。
これをバカ正直にRacketでプログラムすると次のようになる。
;;; 初期化
(define (initialize n)
;;; プレイヤー達(カードのリストのリスト)を生成
(let ((players (dealCards (shuffle-list (make-deck) 7) n)))
;;; プレイヤー達のカードを表示する
(display (showCards players))
;;; 各プレイヤーにペアを捨てさせ、捨てたカードを表示する
(let ((players (map (lambda (x y)
(let-values (((discarded player)
(discardPair y)))
(display
(showDiscardCards x discarded))
player))
(range (length players)) players)))
;;; 現時点でのプレイヤー達のカードを表示する
(display (showCards players))
;;; world構造体の初期値を返す
(world #f (make-clist n) '() '() 0 1 players))))
基本的に設定 -> 印字、の繰り返しでプログラム的には実の事を言うとあまりスマートではない。
が、所詮スクリプト程度なんでそれで良いのだ。
印字関係に於いては前にprint関数用に作った文字列整形関数を流用出来るので手間は大してかからないだろう。
もうちょっとだけ細かく見ていく。
変数playersは後にworld構造体に格納されるため、のカードのリストのリストが束縛されるわけだが、初期化プロセス上、2段階に分かれて束縛されている。
1回目はカードデッキ生成、カードのシャッフル(※2)、カードディールを経た結果を束縛されている。この時点で、例えば4人打ちを想定した場合、14枚、13枚、13枚、13枚、と言うカードのリストが束縛されているわけだ。そしてこの段階で一回目の印字を行う。
2回目は各プレイヤーに生成されたペアを捨てさせる作業だ。高階関数mapの出番で、プレイヤーのリスト、つまり1回目に生成されたplayersを相手に一気に処理してしまう。
及び対象として(range (length players))と言うリストも使ってるが、これも例の如く「プレイヤー番号」を格納したリストである。
ここでの注意点は、ラムダ式の中でdisplayが使われてる辺りだ。
「あれ、displayは副作用だから、mapを使うんじゃなくってfor-eachを使うべきじゃ・・・?」
確かに良くあるパターンでは、displayと良く組み合わせる高階関数はfor-eachである。ただし、これはその「良くあるパターン」ではない。むしろfor-eachを使うと結果がおかしくなってしまうのだ。
ここのラムダ式、は単なる副作用目的ではなく、返り値を返す事が求められている。何が返り値なのか、と言うと多値関数discardPairの返り値の一つであるplayerなのだ。ここがプレイヤー一人一人がカードのペアを捨て去った状態を表している。
ラムダ式の内側で多値関数discardPairは与えられたy(つまり1回目に作成されたplayersの各要素)を処理し、「捨てられたカード」と「ペアを捨て去ったy」を同時に生成する。
前者はdisplayが要する情報だが、これは出力さえ終われば捨て去って良い情報だ。つまり、こっちはまさに「副作用絡み」なのである。このラムダ式の真の目的は、「ペアを捨て去ったy」で、つまりplayerを返す事こそが主作用なのだ。
playerを返しさえすれば、mapはplayersの各要素をdiscardPairで加工したリストを生成する。つまり「カードのリストのリスト」がまたもや生成されたわけで、これがここで新たに定義されたplayersリストになる。
そしてこの2回目のプロセスで得られたplayersリストこそが、ゲームを始める際に、初期化されたworld構造体のplayersスロットとして僕らが必要なデータなのだ。
いずれにせよ、主作用/副作用を考える際には「今本当に必要な情報/返り値が何なのか」良く考えること。
とは言っても何故に副作用と呼ばれるのか、と言うと、言い換えると「プログラムの処理に対しては本質的に重要じゃないから」だ、と言う言い方も可能だ。
そう、ビックリするかもしれないけど、出力、と言うのは「計算」って言うコンピュータの本懐に対しては大して重要な作業ではないのである。
困った時はとにかく「返り値が何なのか」考えよう。熟考した挙げ句「あれ?返り値必要ねぇじゃん」となった時のみ、副作用だけ使えば良い。
そしてこの初期化プロセスで忘れちゃならないのは、最後にworld構造体を初期値で組み立て返す、事である。これを忘れちゃ「仏作って魂入れず」になる。
とにかく出力なんかの「副作用」は人間が目にするブツを出すので、ついついそれだけに構いがちになるが、繰り返すがプログラミングに於いては出力自体は大して重要じゃないのである。
極論、プログラム設計とは「何を返り値として返すのか」設計する事である。出力なんざ無くて構わないのだ。いやマジで(笑)。
出力形式にこだわって足元取られて何やってるんだか良く分かんなくなるくらいなら「計算はするけど何も表示されないプログラム」を書いた方がマシなのだ(笑)。いや、ホントだって(笑)。
いずれにせよ、出力に凝る前に返り値をどうするか考えよう。出力は後回しでどーにでもなるし、だからこそそれは「副作用」なのである。
さて、これで初期化プロセスを作る事は終わった。
一回、関数initializeの動作テストをしてみる。

各プレイヤーの状態遷移の出力後、返り値としてworld構造体の初期値が返る事が確認出来る。
ここまで終われば、早速REPLを改造して動作テストしてみよう。
;;; REPL 第4版
(define (oldmaid n)
(let loop ((w (initialize n))) ;; ここを改変する
(if (game-ends? w)
(display (showResult (world-id1 w)))
;;; Read-Eval-Print loop(loop (print (world-go (input w) w))))))
Racketのリスナーに(oldmaid 4)を与えて実行してみる。

最初の入力を行う前に、Python原作と同じように初期化プロセスの情報が表示され、REPLがスタートするのが分かるだろう。
これでPython原作のスペックに到達した(※3)。一応完成、である。
14. REPLを完成する
ところで、Python原作だと次のようなエラーにお目にかかる事がある。
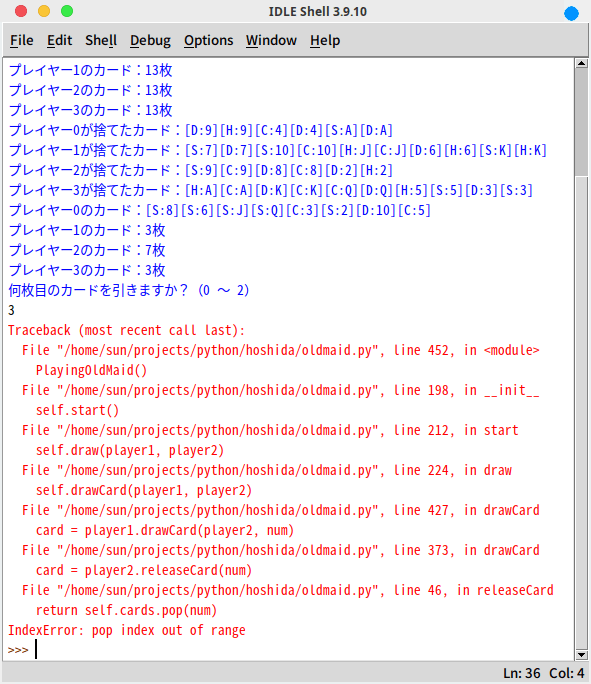
あるいは。

である。
そう、プログラムが想定してる整数の範囲以外の数、あるいはそれ以外の、例えば文字なんかを入力するとプログラムはエラーを吐いて止まってしまうのだ。
もちろん、今のRacket版も同じ、である。

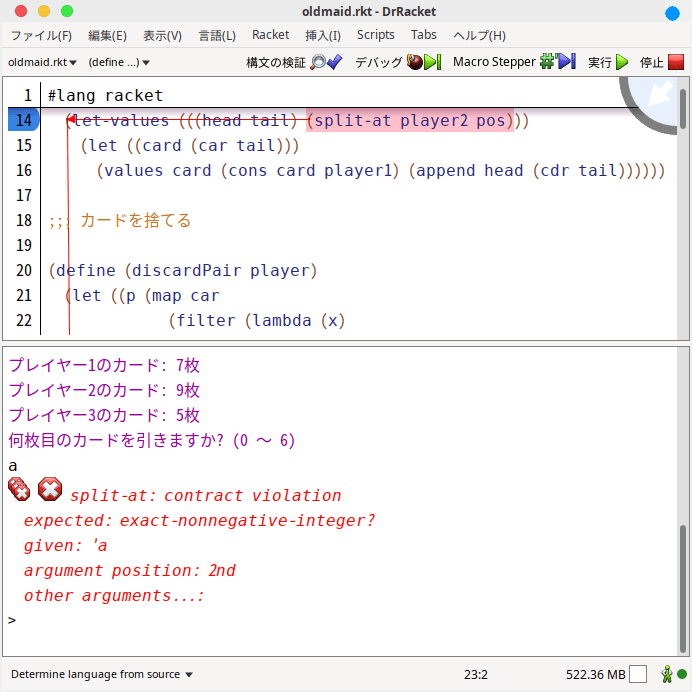
うわ、バグまで再現出来て俺って天才wwwww
って喜んでんじゃねーよwwwww
これは由々しき問題、である。
問題は、貴方はプログラミングでコンピュータの挙動をコントロールする事は可能だが、一方、ユーザーが何を入力するか、まではコントロールする事が出来ない事、にある。
そして言っちゃえば、ほぼ100%、ユーザーは貴方の想像の斜め上の入力を行うのである。間違いない。
さて、こういうエラーだが、最近では「例外を投げられる」と言う。
当然、「例外を投げられる」とプログラムはそこで止まってしまう。
しかし、プログラム作成者側としては、エラーが起きた場合、そこでプログラムが止まるのではなく、ユーザーに「適切な入力を促し」、プログラムには処理を継続して欲しいわけだ。
言い換えるとエラーが起き「例外が投げられた」時点で、その情報をキャッチし、適切な処理を施す、と言うような事後処理を行えればありがたい。
これを「例外を捕捉」し「例外を処理する」と表現する。
そしてこれらを合わせて単に「例外処理」と呼ぶ。
元々、古典的なプログラミングでは、例えば想定された入力以外が来た場合に備えて「条件分岐」を使って適切な入力を促すようなプログラムを書いていた。言わば「転ばぬ先の杖」、エラーが起きないようなプログラミングを目指していたのである。
ただし、これはメンド臭いのだ。実際、「あらゆるエラーを最初に想定して」網を貼っておく、ってのは不可能に近い。ユーザーが「貴方が想定する事の斜め上の入力を必ずする」前提だと、そもそも想定自体が不可能だ、って事にならないか。
つまり、そうじゃなくて、明らかにエラーが起きた、と言う時点から「事後処理」を考慮した方が考え方としては簡単になる、と言う事だ。エラーは必ず起きる。起きる以上起きた場合のケースを想定すれば良い。
- 古典的なプログラミング -> 「エラーが起きないように」プログラムする
- 例外処理を使ったプログラミング -> 「エラーは必ず起きるのだから」、起きたエラーに対してどうするか考えるプログラミング
言わば、発想としては一種真逆になるのである。
そしてもう一つ。あまり初心者向けの例外処理の説明には書いてないのだが。
初心者向けの例外処理の説明は基本的に「例外処理の使い方」、要するに構文に付いて書き、そしてエラーの「投げ方」しか書いてない。
そしてその構文説明だと、ぶっちゃけ
「あれ?じゃあ条件分岐と一体何が違うの?」
とハッキリしないのだ。「条件処理の変化球」だけだと旨味が全く感じられないだろう。
ハッキリ言っておく。例外処理の優秀なトコロが何なのか、と言うと、例外が投げられた時点でエラーが起きる「直前」の状態が保存されてる事、なのである。
つまり、エラーが起きた時、そのエラーが起きる前に「状態」を「巻き戻せる」と言うのが例外処理の本当の威力なのだ。
ちょっとここで「バグがない」理想のプログラムに関して考えてみよう。
上の例で見たような、想定外の入力が成された時、ババ抜きプログラムが止まってしまう、ってのは実はホントの事を言うとバグではないのだ。
プログラムはキチンとババ抜きのゲームを進行してるし、ユーザーに対しては「ある範囲の数値」の入力を促している。つまり、ユーザーが勝手に仕様の範囲外の行動をしただけ、である。まぁ、ハッキリ言っちゃえばユーザーが悪いのだ。
ただ、ここでクレーマーと言い合いしても不毛なだけ、である(笑)。これが第一点。商売としてプログラムを書いて大量に売りたいのに、コンピュータにそこまで明るくない人に
「マニュアルを熟読して仕様をキチンと理解して使ってくれ。仕様外の事をやって損害を受けても責任は持たん。」
とか言っちゃって商品の売り上げが下がっても商売的には困るだけ、である(笑)。
要するに「不親切なプログラムは売れない」のだ(笑)。
そうすると、先程書いた通り、「ユーザーは仕様範囲外の入力をするものだ」、つまり、エラーは必ずその時点で起きるだろう、と言う事を想定した方が良い、って事になる。
もう一つ。Read-Eval-Print Loopと言うモデルを考えよう。Read->Eval->Printと言う一連の流れに於いて計算ミスが起きる、とかあるいは「動かない」場合はこれは明らかにプログラムのミスである。つまり、バグだ。
つまり、このシンプルなモデルでのルーピングに不具合があった場合、と言うのは明らかに貴方の責任となる。どっかで設計をミスったのだ。
しかしながら、モデルがシンプルである以上、スパゲティコードで作成したプログラムに比べると「計算ミス」等のバグを探して潰すのは比較的簡単だ、って事になる。
と言う事は、REPLと言うモデルを採用する以上、今までの議論により「プログラムの不具合」が起きる場所、ってのは完全に確定する。やっぱり「ユーザー入力自体の不具合」しかあり得ないのだ。本体のバグではない、って事になる。
言い換えると、REPLと言うのは一種閉じたモデルの為、REPLプロセスさえ上手く動いていたら「不具合を起こす場所」は入力部分だ、と確定出来るので、例外処理、と言うトラップを置く場所は自ずとから決まる(※4)。
Gが出るから、ってぇんでアッチコッチに闇雲にゴキブリホイホイを置かなくて良いのだ。家を綺麗にしてる、って前提なら怪しい場所たった一つに設置しちゃえば、勝手にGはそこにかかるのだ。
Racketではwith-handlerと言うマクロを用いて例外処理を記述する。
(with-handler ((想定する例外1 対応する処理1) ...) 本体)
見かけはちょっとletに似てるかもしんない。
「想定する例外」と言うのは、自分自身で作る事も可能なんだけど、Racket提供者が想定してるものがいくつかある。有名なトコでは「ゼロ除算」とかな。

でもこの「例外にいくつも種類がある」と言うのが初心者を億劫にさせるのだ。
「何個も例外を暗記しないといけないの?」
と。
だから例外処理を使いたがらなくなる。これはPythonでもそうなんだ。
一つTips。実際にエラーを起こしてみれば良いのだ。
例えば上でのRacket版ババ抜きでのエラーを見てみよう。


これらは両者ともcontract violationと言うエラーで、平たく言うと、これが例外名、である。つまり原則、プログラム上ではこの名前で例外を捕捉するのだ。
言い換えると、この名前でマニュアルから例外を検索すれば良い。

プログラム上はexn:fail:contractと言う名前になってる。
そして、with-handlerの「想定する例外」には述語が入るのだが。
Racketの例外は全て構造体で記述されてるデータ型、となってる。つまり、構造体である以上、それらは全て「型」を持っていて、また、構造体は自らの型をチェックできる「述語」を自動生成する。
言い換えるとexn:fail:contractと言う型にはexn:fail:contract?と言う述語が「必ず」あるわけだ。これを利用する。
そして「対応する処理」はラムダ式で記述する。今回の場合は「不正な入力です」とでも表示して、何喰わぬ顔をしてループを続行すれば良い。
具体的にREPLに例外処理をぶち込んでみよう。これがREPLの完成形、である。
;;; REPL
(define (oldmaid n)
(let loop ((w (initialize n)))
;;; ここで例外処理を記述する
(with-handlers ((exn:fail:contract?
;;; 例外処理
(lambda (ext) (display "入力が不正です\n")
(loop w))))
;;; 本体
(if (game-ends? w)
(display (showResult (world-id1 w)))
;;; Read-Eval-Print loop
(loop (print (world-go (input w) w)))))))
実行してエラーを起こそうとすれば次のようになる。

おかしな入力をしようとしても「入力が不正です」と表示して微動だにしない。
そして例外処理では(loop w)と言うかなり曖昧な記述を施した筈だ。しかし、例外処理機構with-handlerは「例外が投げられる直前の状態」を記憶している。今入力をしようとしてた、のだ。だから何喰わぬ顔で再度プロンプトを表示してユーザーに入力を促す。
なるほど確かに「状態が巻き戻って」いるのである。
そしてこれを古典的に条件分岐で記述しようとすると極めてメンド臭い事になるのは想像に難くない。
さて、これでRacketによるババ抜きのプログラムは晴れて完成、である。全三回に渡って解説してきたが、読んでくれた人、お疲れ様。
そしてREPLと言うソフトウェア記述上のモデルが如何にシンプルで、応用性が効き、バグが混入しづらい、と言う事が少しでも伝われば幸いである。
なお、ここに今回のババ抜きプログラムの全ソースコードを上げておく。
※1: ところで、このinput関数は入力以外、つまり「余計な計算」を行ってて、REPLの原則(ReadもPrintも余計な事をさせるな)に反してるのでは?と思う向きもあるかもしれない。
しかし、input関数は受け取ったworld構造体そのものを全く改変してないのだ。
繰り返すと、ここで言う「余計な計算」とは、環境、つまりworld構造体の中身を変更するような事をしてるか、どうか、である。
言い換えると、input関数はworld構造体が持ってる情報を利用しているだけ、でありworld構造体自体を新しく算出してるわけではない。避けるべきなのは後者のworld構造体そのものを新しく生成する事、なのである(一般には、構造体スロットの破壊的変更も含まれる)。
また、「入力」と言う意味ではそれが人から、であろうとコンピュータから、であろうと基本同じである。
結果、このinput関数は特にREPLのルールには反していないし、事実上単なる入力関数である(たとえそれがコンピュータから、だとしても)。
※2: ここでは7回シャッフルする、って事にしているが、このプログラム上では特に根拠はない。
一般に、コンピュータ上の乱数プロセスと関係なく、人間がトランプを「切る」場合、数学的には7回も作業をすれば、充分「乱雑な状態になる」と言われてる。
人間がトランプを切るのとコンピュータ上で乱数を用いて「シャッフル」するのを同一視は出来ないが、そんなこんなで、一応「7」と言う数値を与えている。
※3: 実は到達してない(笑)。
Python原作では、他に出力にsleepを用いたウェイト処理、と言われるものを行っている。
これをする事によって出力は一気に表示されず一行一行順次に表示されるようになってるわけだ。
が、僕はこれが嫌いで(笑)、全く意味のない作業だ、って思ってるんで省いた(確かにビデオゲームでのセリフの表示等で使われてるのは良く目にするが)。
気になる人はRacket組み込みのsleepを出力関数printに仕込む事で同じような動作をさせる事は可能だろうが、僕なら死んでもやらない(笑)。
※4: 静的型付け言語 vs. 動的型付け言語、と言う一種フレームがある。
言い換えると「バグが出来づらい言語」 vs. 「プログラムが書きやすい言語」と言う枠組みだ。
Lisp、Ruby、JavaScript、Pythonは後者にあたり、C、C++、Java、Rust、Scala、OCaml、Haskell等は前者にあたる。前者は変数を使う際に変数の型を宣言しないとならない言語だ。
Python人気とは別に、「現時点どう言った言語が新しく生まれてるのか」と言う観点があり、そういう意味では現時点では静的型付け言語の人気の方が上回ってるし、「バグがないプログラムを如何に書くのか、あるいはバグが無いプログラム、と言う証明は?」と言う理論的研究では静的型付け言語に現時点では軍配が上がってるようだ。
ただし、Read-Eval-Print Loopと言うモデルを採用する限り、本体のループ部分でバグが無ければ、どっちの言語で書こうと結果大差が無いような気がしてる。コンピュータ内でのプログラム同士のやり取りは「記述通りに動く」為、理論的には人為的入力ミスは生じないわけだし。
確かに、プログラム記述時のミスに対してアラートしやすい、と言う意味では静的が厳密にやってくれるだろうが、一方、作成時には動的だろうと警告はしてくれるんで大した差でもない。つまり、静的は特に「プログラマの為に」取り立てて働いてくれてるわけでもないのである。
結果、確実に問題が起きるのはやっぱりユーザ入力の部分で、ここで型によっての不具合が生じる想定をすると、静的の方がシンプルに書けるかもしれない、って程度の差しか無いのではないか。そしてREPLモデルを採用する限り、その観点で言うとやっぱ動的型付け言語の「書きやすい」と言うメリットの方が圧倒的に魅力的に見える。
なお、どうしても構造化スパゲティでプログラムを書かないとならないんです!と言う場合は恐らく静的型付け言語の方がマシな結果を導くだろう。
いずれにせよ、言語自体より採用するプログラムのモデルの方が重要なのではないだろうか。
※5: なお、標準Schemeには例外処理は長らく存在しなかったが、最新のR7RSでは導入されている。しかし、Racket版はそれとは(機能的には同じだが)違う事に留意しよう。
なお、Schemeに例外処理が存在しなかったのは「ユーザーが"継続"を使えば自作出来る」と言うのが理由だった。非常にミニマリスティックな観点で例外処理を排してきたのである。
こう言う、通常は「言語製作者しか作れない」ブツをユーザーが作れてしまうのがLisp族の恐ろしいトコであり、と同時に過激なDIY指向はユーザーを遠ざけてしまう、と言う一例でもある(もっともANSI Common Lispには「何でもある」・笑)。