妙なタイトルだが、星田さんの記事名から、だ。
星田さんのブログの記事を読んでたら、横にある「人気記事」の中にこの記事が入っていた。二年以上前の記事がいまだに人気で読まれているようだ。
僕も読んでみたら、そこに記述されている問題が、単純だがなかなか面白い。
引用しよう。

二年以上前だと星田さんも苦戦したようだが、二年以上前に苦労しても今苦労するたぁ限らない。
しかも二年以上前だと武器はPython一本槍だったろうが、今ならScheme/Racketがある。
従って、二年以上前より武力的には充分上回ってる筈である。
よってこれをRacketでやっつけてみよう。
さて。ところで。
星田さんによると、出題側のPaizaで解答例が表示されてる模様。
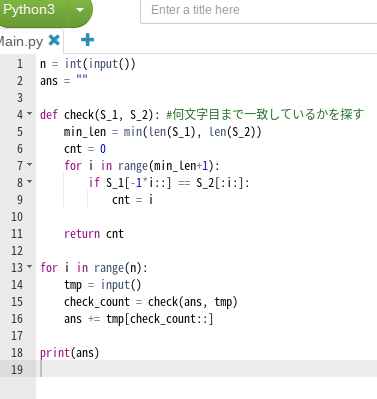
さぁ、みんな。これを読んで一体どう思うだろうか。
ロジック自体に問題はないだろう。
しかしこれを見て、
「やだなー、やだなー、やだなー」
「変だなー、変だなー」
「怖いなー、怖いなー」
「おかしいなー、おかしいなー」
「変だなー、変だなー」
「怖いなー、怖いなー」
「おかしいなー、おかしいなー」
と稲川淳二状態にならないとダメなのだ。
そう、いっつも腐してるが、これは腐れC言語脳が書いたコードだと見抜けないとダメだ。
100歩譲っても、様式美がまるでない、って事に気づかないといけない。唐突なinput関数の使用、とかまるでド素人が書いたようなコードだ。
いや、普段なら何も言わねーよ。ホントにド素人が書いたかもしれないし。
しかし、曲りなりにも教育機関を名乗ってるトコで働いてるヤツがこんなコードを書いてたらダメだろ、ってな話だ。教える側は学生が真似すべきスタイルで記述するべきなんだっての。当たり前の話だろ、って。
どこの書道の先生がお手本にクソみてぇな下手糞な文字を書くか、ってな話だ。こういうのを見るとpaizaはやっぱクソみたいなPython書きを量産してるだけなんじゃねぇの、って思う。それくらいダメなコードだ。
そもそも取って付けたようなans変数の使用と関数使用に始まり、ans変数を破壊的変更してやがる・・・・・・。ホントにそんな事必要か?もっとスマートに書けるんじゃねぇの?
こんな腐れC言語みたいなコードを書くくらいだったら初めッからC言語を教えるべきで、Pythonなんかを教える必要はないんだ。っつーかこれはPythonを「使えてる」とは言わない。そしてこんな汚いコードを提示して「Python教えてます」とか片腹痛いわ。
ヘソで茶が沸くぞ、コラ(怒
と言うか、こういう腐れC言語脳の奴らに影響を受けたくなかったら、やっぱプログラミング初学者はSchemeとかもっとマトモなプログラミング言語をまずは学ぶべきだ、って思う。
分かったろ?だから今、日本のPython周りはメチャクチャなんだっての。プログラミング初心者はPythonを避けた方がいい、って言ってる理由はこのブログを読んでる人は良く分かると思う。
ホンマ、バッカじゃねーの、だ。
まずは基本から行こう。Racketの関数、substringを使う。

問題の最初の例示に従うと、"paiza"と言う文字列と"apple"とあったとして、
> (substring "paiza" (- (string-length "paiza") 1))
"a"
> (substring "apple" 0 1)
"a"
>
となる。"paiza"の方はケツにあたる部分文字列(substring)が返り、"apple"の方はアタマにあたる部分文字列が返る。
両者共"a"が返り、部分文字列は一致する。問題は、一文字だけの部分文字列ではなく、ある程度まとまった部分文字列が一致するかどうか調べないといけない。つまり、返すべき部分文字列は、"paiza"の方はケツからアタマに向かって、"apple"の方はアタマからケツに向かって、徐々に長くなっていかないといけない。
情報としては「一致しなくなった」位置が一体どこなのか、と言うのが重要になる。
ちと表として見てみよう。

cnt = 1の時は両者とも指定された部分文字列は"a"で一致してるが、cnt=1以降にそれが壊れる。cnt = 1以外はstring-ci=?(※1)は#fを返し続ける。
もう一つ問題文の例示に従ってパターンを見てみよう。

今度はcnt = 1の時点で指定された部分文字列は一致しないがcnt = 2 の時、部分文字列が一致する。以降は一致しない。
つまり、2つの部分文字列を走査していき、#tがあったとしたら#tが#fに切り替わる直前の位置情報cntが何なのか、と言うのが重要になるわけだ。
いずれにせよ、string-ci=?の評価値が#tから#fへと切り替わる前の場所cntを使って、(string-append "paiza" (substring "apple" cnt))、そして(string-append "paizapple" (substring "letter" cnt))を返せば良い。
部分文字列を伸長させる為には繰り返し処理を行わないとならない。この辺、名前付きletを使うとかdoを使う、とかは任せよう。各自自由にやってみればいい。
ただし、このブログでは例によって、反復処理を直書きするのはメンドくせぇの法則により、高階関数foldlを用いる。
今までのインタプリタ上で実験してきたsubstringの作用を考えると、概形としてはこういう関数を書いてみれば良さそうじゃねーの、とか言うのを思いつくんじゃないか。
最初のパターンはこう。
(foldl (lambda (cnt init)
(match init
(`(,s0 ,s1 ,i)
`(,s0 ,s1
,(if (string-ci=? (substring s0 (- (string-length s0) cnt))
(substring s1 0 cnt))
cnt
i)))))
'("paiza" "apple" 0)
(range 1 (add1 (apply min (map string-length '("paiza" "apple"))))))
2番目のパターンはこうだ。
(foldl (lambda (cnt init)
(match init
(`(,s0 ,s1 ,i)
`(,s0 ,s1
,(if (string-ci=? (substring s0 (- (string-length s0) cnt))
(substring s1 0 cnt))
cnt
i)))))
'("paizapple" "letter" 0)
(range 1 (add1 (apply min (map string-length '("paizapple" "letter"))))))
今は具体的な文字列を当てはめてるが、いずれにせよ、骨格は共通している。
ポイントをいくつか見てみよう。
今は、サンプルとして継続して"paiza"と"apple"と言う文字列、そして"paizapple"と"letter"を用いるが、これらが成すリストのcdrにカウンタ記録用変数をセットした変数をfoldlの初期値にする。カウンタ記録用変数は0にしてある。
このリストはfoldlのラムダ式の仮引数initに手渡される。そしてmatchでそのリストにある3要素はそれぞれ、s0、s1、iと言う変数名で束縛される。
ここは本来ならletで地道に変数として束縛される面なんだけどメンド臭いからmatchを使った。
「え、これってパターンマッチなのか?」
って思うかもしんないけど、一応パターンマッチではある。ただし「パターンに拠る」分岐処理を行ってないだけ、だ。
そんな事やっていいのか?って思うかもしんないけどやって良い。ハッキリ言うと、ANSI Common Lispで言うトコのdestructuring-bind代わりにmatchを使ってる(※2)。
いずれにせよ、それを使う事によってコードを書く手間が減るのなら、本来の目的から若干ズレるにせよガンガン使うべきだ。何故ならマクロ展開が起こるなら計算負荷は生じない(※3)。
さて、初期値リストを要素に分解したら、あとはカウンターリストから受け取った変数cntを利用してs0、s1の部分文字列を比較する。部分文字列が一致したら場所変数iをcntの値で更新して、そうじゃなかったら何もしない。重要なのは最後に更新されたiの値だ。そこさえ把握しておけばロジックはさして難しくないだろう。
あとはカウンター用リスト作成だけ、だ。2つの文字列の内、短い方の文字列の長さを最大値としてrangeでカウンター用リストを作る。
> (range 1 (add1 (apply min (map string-length '("paiza" "apple")))))
'(1 2 3 4 5)
> (range 1 (add1 (apply min (map string-length '("paizapple" "letter")))))
'(1 2 3 4 5 6)
>
両者とも1から始まった短い方のリストの長さと同じ昇順の整数リストを返す。当然意味は、前者は「1文字目、2文字目、3文字目、4文字目、5文字目」で、後者は「1文字目、2文字目、3文字目、4文字目、5文字目、6文字目」だ。これをfoldlのラムダ式の仮変数cntに順次手渡していき、結果、ラムダ式内のsubstringに「どういう長さの部分文字列を生成するか」指定する役割を持つ。
結果、上のコードサンプルだと、最初の例では
'("paiza" "apple" 1)
が返り値となり、2番目だと
'("paizapple" "letter" 2)
となる。
単純には、前者は
(string-append "paiza" (substring "apple" 1))
を構成する材料で、後者は
(string-append "paizapple" (substring "letter" 2))
を構成する材料だ。これらの計算結果は題意を満たしてるのが分かると思う。
さて、ここまで来れば問題を解くエンジンはほぼ制作完了だ。
あとは、不特定多数の文字列を受取り、粛々と今まで書いてきた「仕組み」に手渡す「枠組み」をでっち上げれば終了、となる。
結論から言うとコードは次のようになるだろう。
(define (programming048 . args)
(foldl (lambda (s-2 s-1)
(string-append s-1
(substring s-2
(foldl (lambda (cnt init)
(if (string-ci=? (substring s-1 (- (string-length s-1) cnt))
(substring s-2 0 cnt))
cnt
init))
0
(range 1 (add1 (apply min (map string-length `(,s-1 ,s-2)))))))))
(car args) (cdr args)))
インタプリタ上での実験では使ってたmatchが消えてしまった。と言うのも実験では具体的な文字列を与えてたが、foldlを外側に置いた際に、ラムダ式の仮引数が操作対象の文字列を保持してくれるようになったんで、内側の「エンジン」部分ではそれを単に受け取って処理するだけで良くなったから、だ。
また、そのお陰で、内側の「エンジン」はカウンターだけ気にすれば良くなり、結果、外側のfoldlのラムダ式は文字列生成だけに注力すれば良くなった。
関数programming048は文字列を可変長引数として受け取る。あとは先程書いたロジックを上で書いたように改造しfoldlのラムダ式で包んでる(結果二重foldlとなる)。内側のfoldlの初期値は単に0だ。
先程書いたロジックの改造版が数値(適当にiと呼ぶがコード内では現れない)を返すのは既に見た通りだ。そして(string-apend s-1 (substring s-2 i))で文字列を構築し、それを外側のfoldlの次の初期値としてセットする。foldlのラムダ式の返り値は常に初期値を更新していくのを思い出そう。
あとは今まで具体的に与えてた文字列をラムダ式の仮引数、s-1、s-2で置き換えておけば良いだけ、だ。そうすれば具体的には例えば、プログラムに与えられた可変長引数が"paiza"、"apple"、"letter"の3つとして
"paiza" '("apple" "letter") -> "paizapple" '("letter") -> "paizappletter" '()
と外側のfoldlの初期値とリストが更新されていく。そして"paizappletter"が最終的な返り値となり、解題だ。
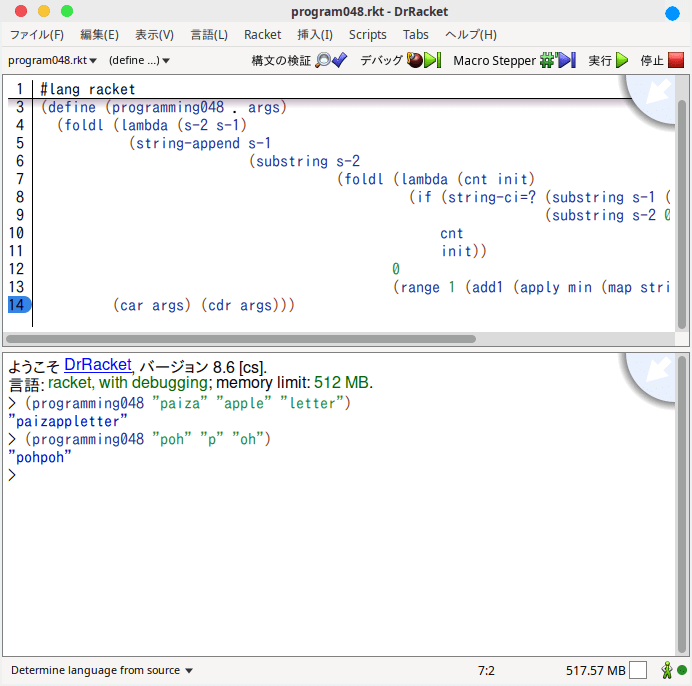
終わってみれば大した問題でもないだろう。foldlが難しく感じる人はフツーに再帰を書いていっても良い。いずれにせよ、エンジン部分が上手く書けるか否か、がキーとなる。
一応、ここにソースコードをあげておこう。
なお、同様のロジックを使ったPython版は次のようになる。
from functools import reduce
def programming048(*args):
return reduce(lambda s_1, s_2:
s_1 + s_2[reduce(lambda init, cnt:
cnt if s_1[-cnt:] == s_2[:cnt] else init,
range(1, 1 + min([len(i) for i in [s_1, s_2]])),
0):],
args[1:], args[0])
ここに端末で走らせられるようにしたソースコードを置いておこう。

おしまい。
※1: string-ci=?は大文字と小文字を区別しない。つまり、"A"と"a"は一致する。
問題の仕様には含まれてないが、文字列比較にこれを使う事とした。
Pythonでのアンパックも構造化代入の一種と考えて良い。また、C++でも同様の機能が提供されている模様だ。
※3: 厳密に言うと生じる(笑)。何故ならSchemeにはコンパイラが無いから、だ。
マクロはコンパイル時に、ソースコードをマクロ定義に従って書き直すのと同じ事を行うので、実行時には負荷がかからないんだが、仕様上Schemeにはコンパイラがないので、この論はSchemeでは画餅となる。
ただし、RacketはScheme方言であってSchemeそのものではないし、一応独自仕様のコンパイラを持っている。
このコードをコンパイルするかどうかは使用者に拠るけど、「コードを短くして明解性を上げる」方がトレードオフが生じるにせよ全般的には書き手へのメリットになるだろう。