最近,暇が無くて困っています.前回より,二ヶ月以上も更新できていません.
今回は,Rを使った簡単な統計の説明をさらします.
その後,QC7つ道具の説明をさらせたらいいな・・・.
(多分 2ヵ月後ではないかい?)
実は,最近 Michael Crawleyさんが書いた"Statistics -An Introduction Using R"が,下のような流れで統計の説明をスタートさせていて,結構わかりやすいなあと関心しました.
1.文書での説明
2.数式での説明
3.Rで公式通りにプログラムして説明(数値例含む)
4.Rの関数があれば,それでの結果(数値例含む)
さすがに,この 4段階で説明すれば,わかりやすくなるでしょうし,何よりも手を動かしますので,覚えやすいでしょう.
(鉛筆動かしても,計算間違えて「はまって」しまう事もありますので,統計なんかは,自分でプログラム組んだ方がわかりやすいと思います.)
ちなみに,[1]とかは,Rからの返答です.
このデータは,私が昔に測定したスイッチの動作荷重です.
(数字が丸まっているのは,手書きのグラフから目視で取ったからです.)
スイッチ荷重(g)
このデータを sw.force という変数に入れます.
データの個数は,よく n で表します.
Rでは,以下のように調べることが出来ます.
∑記号は,以下の意味です.
∑ x = x1 + x2 + x3 ・・・・ xn
つまり,x で表されたデータをすべて足したものです.
(次の総和を見れば判るでしょう)
データの総和は,上記のデータをすべて足したものです.
つまり,下記の式のようになります.
総和=∑ 個々のデータ
Rでは,データ sw.force を下記のようにして,
で計算できますし,関数を使って,
でも計算出来ます.
平均は,当たり前ですが,
平均=総和/データの個数
ですよね.
Rでは,
と公式通りやっても計算できますし,
と,関数を使っても計算できます.
平方和とは,個々のデータのデータの平均からの差を表す統計値です.
素直に,∑ 個々のデータ-データの平均 とやると,合計は 0 になりますので,
個々のデータ-データの平均 の2乗した数を足し合わせたものを平方和と定義します.
平方和=∑(個々のデータ-データの平均)^2
Rで計算すると,(個々のデータ-データの平均)^2 は以下の100個のデータですから,
これを全部足したもの
です.
ここら辺,説明が妙なので全面改訂します.(2006/5/28)
自由度とは,データの個数-1です.(とは限りませんが,この場合の自由度はこうです)
なぜ,データの個数から1を引くのでしょうか?
それは,各データを見比べる時(統計量とかというやつ)に,決定した変数(平均とか)を固定した時の,その変数の変化できる度数をその変数の自由度と呼びます.
簡単に考えると,各データの特徴を決める変数(平均とか)が牧場を囲っている杭だとすると,その変数の自由度とは,その杭(変数)を打ち込んだときの本数で,それ以外の変数の自由度は残りの杭の個数の事だと考えるとわかりやすいかも知れません.
今回は,平均を決めた(つまり,杭を1本打ち込んだ,つまり平均に対する自由度は1)ので,自由度が1つ減り,残りの自由度(分散とかを決定するのに使用できる自由度)はデータの個数-1=99となります.
ほら,判りづらいでしょう.やはり,初めのうちは,データとデータの間の個数(杭と杭との間の個数)と考えて,そのうち杭と杭の間の個数を固定すると……とか考えた方が,わかりやすいような気がします.(そして,最後には正しい定義を覚える……と.)
まあ,色々な変数を決定する時に,どれだけ変わりやすいかを意識していじると,そのうち体で覚えてくるような気がします.(私も時々間違えます……orz)
Rでは,以下のように表せます.
上の改定に基づき,一寸改定.(2006/5/28)
分散は,その平方和を残りの自由度で割った値です.(残りの自由度とは,上で平均を決めるのに使った自由度1を引いた自由度です.)平方和は,そのデータ全体のバラツキを表す方法ですが,分散は,各データの(平均的な)バラツキを表す値になります.
分散 = 平方和/自由度 = ∑(個々のデータ-データの平均)^2 / データの個数-1
Rでは,
と公式通り計算できますし,
と関数を使っても計算出来ます.
分散は,実はそのデータの 2乗の単位になってしまうので,単位をあわせるために
√すると,単位が合います.これを標準偏差といいます.
(かなり乱暴な説明ですが)
これをσと呼ぶことが多いです.
(そう,モトローラやGEでやっている,6σの σ です.)
標準偏差 (σ)= √分散 = √(∑(個々のデータ-データの平均)^2 / データの個数-1)
Rでは,
とも出来ますし,関数を利用して,
とも出来ます.
3σ限界は,何のことは無い,±3×標準偏差 です.
この範囲内で,データに癖(データの上昇・下降傾向,平均より上側傾向・下側傾向等)が無ければ,その工程は安定していると見ることが出来ます.
Rでは,
です.
上管理限界は,平均+3σ限界(3×標準偏差)です.
Rでは,
です.
下管理限界は,平均-3σ限界(3×標準偏差)です.
上は + 下は - です.
Rでは,
です.
工程能力は,その工程での加工能力や設計が,公差(規格)に対して余裕があるかどうかを示す値です.
通常 Cp > 1.33であればOKとなります.
公式は,
工程能力=(上側規格-下側規格)/6σ
です.
Rでは,
とすると,
となります.
今回は,Rを使った簡単な統計の説明をさらします.
その後,QC7つ道具の説明をさらせたらいいな・・・.
(多分 2ヵ月後ではないかい?)
実は,最近 Michael Crawleyさんが書いた"Statistics -An Introduction Using R"が,下のような流れで統計の説明をスタートさせていて,結構わかりやすいなあと関心しました.
1.文書での説明
2.数式での説明
3.Rで公式通りにプログラムして説明(数値例含む)
4.Rの関数があれば,それでの結果(数値例含む)
さすがに,この 4段階で説明すれば,わかりやすくなるでしょうし,何よりも手を動かしますので,覚えやすいでしょう.
(鉛筆動かしても,計算間違えて「はまって」しまう事もありますので,統計なんかは,自分でプログラム組んだ方がわかりやすいと思います.)
ちなみに,[1]とかは,Rからの返答です.
使用データ
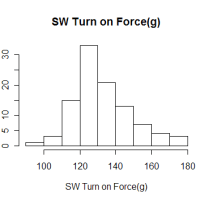
このデータは,私が昔に測定したスイッチの動作荷重です.
(数字が丸まっているのは,手書きのグラフから目視で取ったからです.)
スイッチ荷重(g)
このデータを sw.force という変数に入れます.
sw.force<- c(
95, 105,105,105, 115,115,115,115,115,115,115,115,115,115,115,115,115,115,115, 125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125, 135,135,135,135,135,135,135,135,135,135,135,135,135,135,135,135,135,135,135,135,135, 145,145,145,145,145,145,145,145,145,145,145,145,145, 155,155,155,155,155,155,155, 165,165,165,165, 175,175,175, )
データの個数
データの個数は,よく n で表します.
Rでは,以下のように調べることが出来ます.
length(sw.force) [1] 100
∑記号
∑記号は,以下の意味です.
∑ x = x1 + x2 + x3 ・・・・ xn
つまり,x で表されたデータをすべて足したものです.
(次の総和を見れば判るでしょう)
データの総和
データの総和は,上記のデータをすべて足したものです.
つまり,下記の式のようになります.
総和=∑ 個々のデータ
Rでは,データ sw.force を下記のようにして,
sw.force.total<- 0
for (i in 1:length(sw.force)){ sw.force.total<- sw.force.total+sw.force[i]
} sw.force.total [1] 13250
で計算できますし,関数を使って,
sum(sw.force) [1] 13250
でも計算出来ます.
平均
平均は,当たり前ですが,
平均=総和/データの個数
ですよね.
Rでは,
sum(sw.force)/length(sw.force) [1] 132.5
と公式通りやっても計算できますし,
mean(sw.force) [1] 132.5
と,関数を使っても計算できます.
平方和
平方和とは,個々のデータのデータの平均からの差を表す統計値です.
素直に,∑ 個々のデータ-データの平均 とやると,合計は 0 になりますので,
個々のデータ-データの平均 の2乗した数を足し合わせたものを平方和と定義します.
平方和=∑(個々のデータ-データの平均)^2
Rで計算すると,(個々のデータ-データの平均)^2 は以下の100個のデータですから,
(sw.force-mean(sw.force))^2 [1] 1406.25 756.25 756.25 756.25 306.25 306.25 306.25 306.25 306.25 [10] 306.25 306.25 306.25 306.25 306.25 306.25 306.25 306.25 306.25 [19] 306.25 56.25 56.25 56.25 56.25 56.25 56.25 56.25 56.25 [28] 56.25 56.25 56.25 56.25 56.25 56.25 56.25 56.25 56.25 [37] 56.25 56.25 56.25 56.25 56.25 56.25 56.25 56.25 56.25 [46] 56.25 56.25 56.25 56.25 56.25 56.25 56.25 6.25 6.25 [55] 6.25 6.25 6.25 6.25 6.25 6.25 6.25 6.25 6.25 [64] 6.25 6.25 6.25 6.25 6.25 6.25 6.25 6.25 6.25 [73] 6.25 156.25 156.25 156.25 156.25 156.25 156.25 156.25 156.25 [82] 156.25 156.25 156.25 156.25 156.25 506.25 506.25 506.25 506.25 [91] 506.25 506.25 506.25 1056.25 1056.25 1056.25 1056.25 1806.25 1806.25 [100] 1806.25
これを全部足したもの
sum((sw.force-mean(sw.force))^2) [1] 25475
です.
自由度
ここら辺,説明が妙なので全面改訂します.(2006/5/28)
自由度とは,データの個数-1です.(とは限りませんが,この場合の自由度はこうです)
なぜ,データの個数から1を引くのでしょうか?
それは,各データを見比べる時(統計量とかというやつ)に,決定した変数(平均とか)を固定した時の,その変数の変化できる度数をその変数の自由度と呼びます.
簡単に考えると,各データの特徴を決める変数(平均とか)が牧場を囲っている杭だとすると,その変数の自由度とは,その杭(変数)を打ち込んだときの本数で,それ以外の変数の自由度は残りの杭の個数の事だと考えるとわかりやすいかも知れません.
今回は,平均を決めた(つまり,杭を1本打ち込んだ,つまり平均に対する自由度は1)ので,自由度が1つ減り,残りの自由度(分散とかを決定するのに使用できる自由度)はデータの個数-1=99となります.
ほら,判りづらいでしょう.やはり,初めのうちは,データとデータの間の個数(杭と杭との間の個数)と考えて,そのうち杭と杭の間の個数を固定すると……とか考えた方が,わかりやすいような気がします.(そして,最後には正しい定義を覚える……と.)
まあ,色々な変数を決定する時に,どれだけ変わりやすいかを意識していじると,そのうち体で覚えてくるような気がします.(私も時々間違えます……orz)
Rでは,以下のように表せます.
length(sw.force)-1 [1] 99
分散
上の改定に基づき,一寸改定.(2006/5/28)
分散は,その平方和を残りの自由度で割った値です.(残りの自由度とは,上で平均を決めるのに使った自由度1を引いた自由度です.)平方和は,そのデータ全体のバラツキを表す方法ですが,分散は,各データの(平均的な)バラツキを表す値になります.
分散 = 平方和/自由度 = ∑(個々のデータ-データの平均)^2 / データの個数-1
Rでは,
sum((sw.force-mean(sw.force))^2)/(length(sw.force)-1) [1] 257.3232
と公式通り計算できますし,
var(sw.force) [1] 257.3232
と関数を使っても計算出来ます.
標準偏差
分散は,実はそのデータの 2乗の単位になってしまうので,単位をあわせるために
√すると,単位が合います.これを標準偏差といいます.
(かなり乱暴な説明ですが)
これをσと呼ぶことが多いです.
(そう,モトローラやGEでやっている,6σの σ です.)
標準偏差 (σ)= √分散 = √(∑(個々のデータ-データの平均)^2 / データの個数-1)
Rでは,
sqrt(sum((sw.force-mean(sw.force))^2)/(length(sw.force)-1)) [1] 16.04130
とも出来ますし,関数を利用して,
sqrt(var(sw.force)) [1] 16.04130
とも出来ます.
3σ限界(管理限界)
3σ限界は,何のことは無い,±3×標準偏差 です.
この範囲内で,データに癖(データの上昇・下降傾向,平均より上側傾向・下側傾向等)が無ければ,その工程は安定していると見ることが出来ます.
Rでは,
3*sqrt(var(sw.force)) [1] 48.12389
です.
UCL(上管理限界)
上管理限界は,平均+3σ限界(3×標準偏差)です.
Rでは,
mean(sw.force)+3*sqrt(var(sw.force)) [1] 180.6239
です.
LCL(下管理限界)
下管理限界は,平均-3σ限界(3×標準偏差)です.
上は + 下は - です.
Rでは,
mean(sw.force)-3*sqrt(var(sw.force)) [1] 84.3761
です.
工程能力 (Cp)
工程能力は,その工程での加工能力や設計が,公差(規格)に対して余裕があるかどうかを示す値です.
通常 Cp > 1.33であればOKとなります.
公式は,
工程能力=(上側規格-下側規格)/6σ
です.
Rでは,
# Upper tolerance limit (UTL) (g) 上側規格 utl<- 200
# Lower tolerance limit (LTL) (g) 下側規格 ltl<- 80
とすると,
(utl-ltl)/(6*sqrt(var(sw.force))) [1] 1.246782
となります.
参考文献
- Crawley, Michel, J, Statistics An Introduction using R, 2005,ISBN 0-470-02298-1
- R Development Core Team, R: A language and environment for statistical computing.(Ver. 2.2.1), 2005, ISBN:3-900051-07-0
- 鐵建治, 新版 品質管理のための統計的方法入門, 2000, ISBN:4-8171-0342-6
- 荒木孝治 他, フリーソフトウェアRによる 統計的品質管理入門, 2005, ISBN: 4-8171-9148-1
- 船尾暢男, The R Tips データ解析環境Rの基本技・グラフィック活用集, 2005, ISBN: 4-86167-039-X