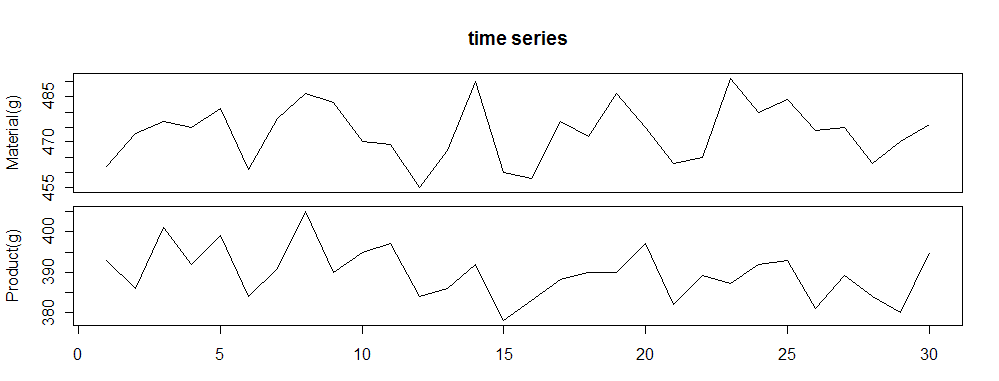
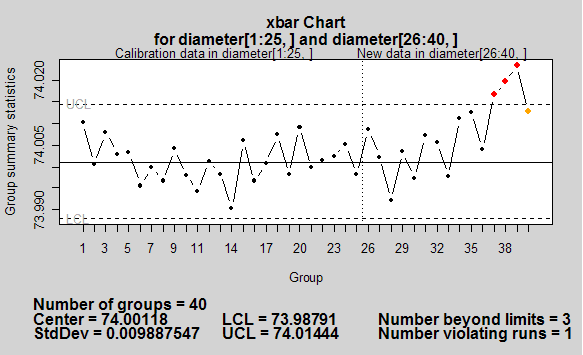
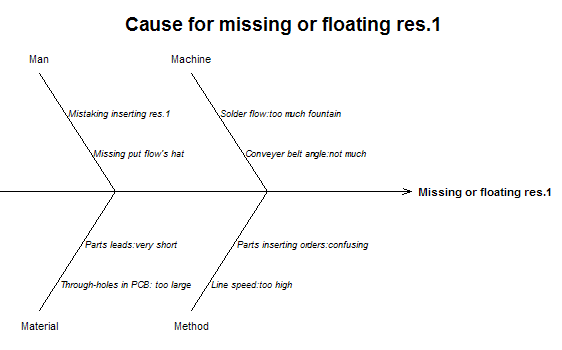
実は新しいPCを買ったので,古いPCにLinuxをインストールしました.
何せふるいPCは,まだWindows Meの時代の奴です.Meは落ちまくるので,強引にXPを入れてました.でも,やはり動きがおかしくなっていました.(画面がキチンと出なかったり,スワップが激しかったり...)
そこで,Linuxの軽い奴はないかといろいろ探した(と言うかインストールしまくった)結果,Knoppixになりました.(でもDebianベースは初めてなので,戸惑いは隠せません.でも,apt-getスゲー.キチンと設定したら,アプリケーションのインストールがメチャ簡単です.)
インストールしてみたLinuxディストロ;
-Momonnga 2(Windows PCでCD-Rに焼いたもの:CD焼きミスでインストールできず)
-Fedora core 3(雑誌の付録 Linuxマガジン2005年1月号)
-Fedora core 5(インストール本 中村真彦,すぐに出来る! Fedora Core 5,2006,
ISBN:4-88166-519-7)
-Knoppix 4.02(雑誌の付録 日経Linux 2006年2月号)
-Knoppix 5.01(雑誌の付録 リナックスワールド 2006年9月号)
Momonga以外すべてインストールは可能でしたが,Fedoraは3,5ともPCMCIAのネットワークカード「コレガ Ether PCC-TD」が動きません.これではNetに繋げられないため,Knoppixに決定しました.(もちろん新しいバージョンの5.01です)
(本当は,Vine 2.6,Kondara 2.1,Plamo 3.0も用意したんですが,やっぱ古くてインストールする気が起きませんでした.)
Knoppix自体はCD Bootしてそのままで走るので,インストールせずに使えるのですが,やはり遅いしCDをシークする音がうるさいしで,インストールしないと実用的ではありません.このPCの場合は,XPのスワップファイルやら,アプリケーションの残骸やらで,20G中19Gも埋まっていたのでした.余計なデータやソフトを外しても15Gぐらい埋まっていたので,XPとのデュアルブートは出来ない感じです.クリーンインストールしかありません.でも,クリーンインストールする方法が特殊なので戸惑いました.雑誌によると,逆にKnoppixはWindowsとのデュアルブートを構築するのは簡単らしいです.
因みにインストールしたパソコンは,IBM Think Pad i1620 (モバイルセルロン 500MHz,HDD 20GB,メモリ192MB)と言うもう7年も経っているノートPCなのです.あの時メモリー満タンにしていてよかった...
PCにクリーンインストールする方法は;
1.とにかくKnoppixを動かす.
2. 端末で,su -とかでrootになって,
3. knx2hdコマンドを動かす.
4. メニューに従ってパーテーション設定する.
(古いパソコンはメモリが足りな気味なので,スワップはメモリの3から4倍ぐらいは入れて
おいた方がいいかもです.因みにKnoppixはメモリ+スワップで512MBないと動きません.)
5. あとはメニューの指示に従って,インストールしていけばokです.
ですが,このままでは「コレガ Ether PCC-TD」が動きません.そこで,/etc/pcmcia/にあるconfigファイル(テキスト)を編集したりします.
1. 端末でrootになり,cd /etc/pcmciaで移動.
2. vi configにてファイルを開く.
3. version "corega K.K.", "corega Ether PCC-T"の行を,
version "corega K.K.", "corega Ether PCC-TD"と編集.
(PCC-TをPCC-TDに変更するだけです.)
4. その下の行が bind "pcnet_cs" となっている事を確認.
(pcnet_csは,このカードを動かすデバイス ドライバです.)
5. ファイルをセーブする.
6. 再起動する.
(/etc/rc.d/init.d/pcmcia restartが何故かワーニング
何かPCMCIAのコントロールプログラムが別のものになっているようなので,
あきらめて(w リブートしますた.)
7. KDEのパネルメニューのペンギンのアイコンから NETWORK/INTERNETの
ネットワーク管理を選び,eth0を選ぶ.
8. 「DHCPブロードキャストを...」でyesを選ぶ.
(固定アドレス等の人は,Noでも選べば何とかなるのでは)
9. Firefoxでも動かして,Netにいけるかどうかを確認する.
(いけなかったら,他のPCでPCMCIAとかでググる or あきらめる)
このあと,apt-getの設定をします.
1. rootで,/etc/apt/sources.listを
http://www.debian.or.jp/Near-Mirror.htmlに従って書き直します.
2. 端末からapt-get updateをします.
この後は,自分の好きなソフトをapt--get install出来ます.
これで,設定はおしまいですが,やっぱRが無いと締まらないので,Rをインストールします.
方法は,rootで,
apt-get install r-base
でokです.後はメニューが出てきた通りにすればいいでしょう.
ここまでくるのに約1ヶ月はかかってます...
何せふるいPCは,まだWindows Meの時代の奴です.Meは落ちまくるので,強引にXPを入れてました.でも,やはり動きがおかしくなっていました.(画面がキチンと出なかったり,スワップが激しかったり...)
そこで,Linuxの軽い奴はないかといろいろ探した(と言うかインストールしまくった)結果,Knoppixになりました.(でもDebianベースは初めてなので,戸惑いは隠せません.でも,apt-getスゲー.キチンと設定したら,アプリケーションのインストールがメチャ簡単です.)
インストールしてみたLinuxディストロ;
-Momonnga 2(Windows PCでCD-Rに焼いたもの:CD焼きミスでインストールできず)
-Fedora core 3(雑誌の付録 Linuxマガジン2005年1月号)
-Fedora core 5(インストール本 中村真彦,すぐに出来る! Fedora Core 5,2006,
ISBN:4-88166-519-7)
-Knoppix 4.02(雑誌の付録 日経Linux 2006年2月号)
-Knoppix 5.01(雑誌の付録 リナックスワールド 2006年9月号)
Momonga以外すべてインストールは可能でしたが,Fedoraは3,5ともPCMCIAのネットワークカード「コレガ Ether PCC-TD」が動きません.これではNetに繋げられないため,Knoppixに決定しました.(もちろん新しいバージョンの5.01です)
(本当は,Vine 2.6,Kondara 2.1,Plamo 3.0も用意したんですが,やっぱ古くてインストールする気が起きませんでした.)
Knoppix自体はCD Bootしてそのままで走るので,インストールせずに使えるのですが,やはり遅いしCDをシークする音がうるさいしで,インストールしないと実用的ではありません.このPCの場合は,XPのスワップファイルやら,アプリケーションの残骸やらで,20G中19Gも埋まっていたのでした.余計なデータやソフトを外しても15Gぐらい埋まっていたので,XPとのデュアルブートは出来ない感じです.クリーンインストールしかありません.でも,クリーンインストールする方法が特殊なので戸惑いました.雑誌によると,逆にKnoppixはWindowsとのデュアルブートを構築するのは簡単らしいです.
因みにインストールしたパソコンは,IBM Think Pad i1620 (モバイルセルロン 500MHz,HDD 20GB,メモリ192MB)と言うもう7年も経っているノートPCなのです.あの時メモリー満タンにしていてよかった...
PCにクリーンインストールする方法は;
1.とにかくKnoppixを動かす.
2. 端末で,su -とかでrootになって,
3. knx2hdコマンドを動かす.
4. メニューに従ってパーテーション設定する.
(古いパソコンはメモリが足りな気味なので,スワップはメモリの3から4倍ぐらいは入れて
おいた方がいいかもです.因みにKnoppixはメモリ+スワップで512MBないと動きません.)
5. あとはメニューの指示に従って,インストールしていけばokです.
ですが,このままでは「コレガ Ether PCC-TD」が動きません.そこで,/etc/pcmcia/にあるconfigファイル(テキスト)を編集したりします.
1. 端末でrootになり,cd /etc/pcmciaで移動.
2. vi configにてファイルを開く.
3. version "corega K.K.", "corega Ether PCC-T"の行を,
version "corega K.K.", "corega Ether PCC-TD"と編集.
(PCC-TをPCC-TDに変更するだけです.)
4. その下の行が bind "pcnet_cs" となっている事を確認.
(pcnet_csは,このカードを動かすデバイス ドライバです.)
5. ファイルをセーブする.
6. 再起動する.
(/etc/rc.d/init.d/pcmcia restartが何故かワーニング
何かPCMCIAのコントロールプログラムが別のものになっているようなので,
あきらめて(w リブートしますた.)
7. KDEのパネルメニューのペンギンのアイコンから NETWORK/INTERNETの
ネットワーク管理を選び,eth0を選ぶ.
8. 「DHCPブロードキャストを...」でyesを選ぶ.
(固定アドレス等の人は,Noでも選べば何とかなるのでは)
9. Firefoxでも動かして,Netにいけるかどうかを確認する.
(いけなかったら,他のPCでPCMCIAとかでググる or あきらめる)
このあと,apt-getの設定をします.
1. rootで,/etc/apt/sources.listを
http://www.debian.or.jp/Near-Mirror.htmlに従って書き直します.
2. 端末からapt-get updateをします.
この後は,自分の好きなソフトをapt--get install出来ます.
これで,設定はおしまいですが,やっぱRが無いと締まらないので,Rをインストールします.
方法は,rootで,
apt-get install r-base
でokです.後はメニューが出てきた通りにすればいいでしょう.
ここまでくるのに約1ヶ月はかかってます...