
星田さんの記事に対するコメント。
まずは軽くジャブとして、雛形を紹介。
前回に従った、関数sum-treeの模範解答を示してみよう。


まず、後で付属的な事をちょっと説明するが、ファイルをモジュールとしている。
モジュール名はsect17-3。Gaucheのレコード型、パターンマッチ機構、ユニットテストの三つを読み込んで、そして外部でsum-tree関数を使えるようにモジュールを設計してる。
そして次にレコード型を利用して、Empty型、Leaf型、Node型の三つを作る。ヴァリアント型である大枠のtree_t型は作らない。前回を見たら分かる通り、静的型付け言語のOCamlと違って、Schemeの関数は元々「どんな型の引数でも」受け取る。従って、ヴァリアント型のような「いくつかの型を1つの型として定義する」必要は全くない、んだ。
ややこしいのは次の部分だ。Gaucheでユニットテストを行う際には、レコード型を採用する場合、自分で等価判定メソッドを書かなくてはならない。しかも今回はレコード型で作ったユーザー定義型が三つもある。従って等価判定メソッドも三つ書かないとならない。
それらの中を見ていく前に、Gaucheのオブジェクト指向はCLOS(Common Lisp Object System)に強く影響を受けてる為、軽くCLOS的な「メソッドの書き方」を見てみよう。
メソッド、と言っても機能的には関数と変わらない。従って似たような書き方になる。
(define-method メソッド名 ((仮引数 型) ...) メソッド本体)
これはANSI Common Lispスタイルなんで、Schemeのdefineとは若干趣が違って見える。
;; Schemeの関数定義(define (関数名 仮引数 ...) 関数本体);; ANSI Common Lispの関数定義(defun 関数名 (仮引数 ...) 関数本体)
「SchemeのdefineとCLOS-likeなdefine-methodはすげぇ違う」って程じゃないけど、Schemeの関数名と違ってdefine-methodのメソッド名は引数リストの先頭には含まれない事に気をつけよう。含まれてない以上、それはANSI Common Lispスタイルだ。
それよりむしろ、define-methodの異常に見える部分は、引数リストの括弧の多さだ。動的型付け言語では型を記述する必要がなかったのに、define-methodは引数に「型」を要求してる為に、やたらカッコが増えてるんだ(let症候群、とでも名付けようか・笑?)。
これは何故か、と言うと、メソッドのパートナーである「クラス作成」の目的がユーザー定義型作成、だからだ。構造体/レコード型の主目的も「ユーザー定義型作成」なんで(※1)、「目的とする型に従って違った演算するのがメソッドの役目」だとどうしても型の情報が必要となる。この辺のちょっとした話もあとに譲ろう。
ところで、C言語系の型名と仮引数名の順序と違う事に違和感を覚えるかもしんない。
C言語だと、
返り値の型 関数名(型 仮引数, ...) {関数本体}
が関数の書式になっている。引数リストを見れば語順が型、そして仮引数になってるが、define-methodの場合、語順が仮引数、型、の並びになっている。
実はコンピュータサイエンス的にはdefine-methodでの並びが正しい。型名は変数名を後方から修飾する、ってのが望ましく、define-methodはそのルールに則っている。
一方、現実的なエンジニアリング言語であるC言語は、ぶっちゃけ、やっつけ仕事で作られてて、設計上のミスを抱えたまま広まってしまった。そして、C言語が広めた「間違い」を、フォロワー(例えばC++とかJava)が尚更広めてしまったんだな。
断っておくと、これは別に悪口ではない。C言語設計者のデニス・リッチー自身が「あれは失敗だった」と語っている。設計者本人がマズかった、と言ってるわけだ。
なお、古くはAlgol、そしてPascalがANSI Common Lispと同様の変数名、型の語順を採用してるし、最近人気のRustも「正しい語順を」採用するようになっている。
さて、次は「等価判定」の中身を見てみよう。
Empty型とEmpty型を比較する場合は、そのまま単純に#tを返しちまえばいい。
Emptyの役目はLispで言うトコのnilみたいなモンで、「唯一存在する値」として判断して構わない。スロットも付けてないしね。
すなわち、仮引数が与えられた時、その型が両方ともEmptyだと分かった時点で「同一である」って判断して構わないわけだ。中身が無い以上それで充分、ってワケだな。
Leaf型が一番オーソドックスな判定法になるだろう。スロットで想定されてる中身は整数型なんで、そこが=なら#tを返す。以上。
ややこしいのがNode型だ。Node型は三つスロットを持っていて、想定は、最初のスロットはまたもやNode型、2番目のスロットは整数型、そして三番目のスロットもNode型となっている。
困るのがスロットの中身がNode型、の部分だ。Node型の中身にNode型が存在する・・・・・・そう、これは再帰的なデータ構造になっている。
と言う事は、今作ってる等価判定述語自体が再帰しないと上手い具合判定出来ないんだわ(※2)。
と言うわけで、object-equal?作成中にobject-equal?を呼び出しながら判定する、と言う病的再帰的な判定関数にしないとならない。
と言うわけで、ユーザー定義型の個数に合わせた三つの等価判定メソッドを書いたわけだが・・・気づいただろうか?名前が全部object-equal?になっている。
通常、大域的に関数を書いた場合、仮に全部関数名が同じだったら、テキストファイルの最後方に書かれた関数「だけ」が有効になるか、あるいはインタプリタ/コンパイラに「馬鹿野郎、書き直せ」と怒られるだけ、だ。
しかし、メソッドの場合は同名で構わないんだ。つまり、「全く同じ名前なのに機能が違う」メソッドが複数同時に定義出来る。平たく言うと、これがオブジェクト指向の強みだ。
ここで定義された同名の三つのメソッドは、そのまま大域変数にある、同名のメソッドの親玉と同化する。もうちょっと細かく言うと、Gaucheが元々持っていたobject-equal?と言うデータテーブルに登録されるわけだ。つまり、仕組みとしては、メソッド名はどっちかと言うと「どのデータテーブルに自らを属させるか」のキーワードとして働いてる、って考えて良い(※3)。
そしてそれ故に、define-methodの仮引数には型情報が必要不可欠なんだ。この場合、親玉のobject-equal?は与えられたデータの型に従って、正しく合致したobject-equal?(子分)を選んで適用する。
要は、我々が作ってたのは分身、っつーか子分なんだよな。
そしてこれがANSI Common Lisp的なオブジェクト指向のメソッドの仕組み、だ。
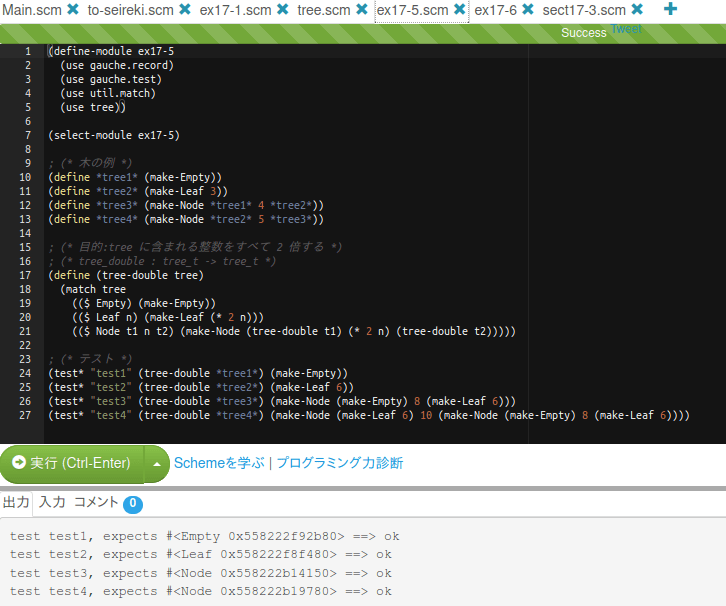
さて、残りの演習の解は以下のようになる。

treeモジュールの定義

さて、星田さんの疑問に答える前に、PaizaとGaucheのモジュールの関係をちと書いておこう。
色々試してみたら、結果、Paiza上で作成したファイルは全部、Linux上の作業フォルダ内の同レベルにあるようなカタチになっていて、ファイル同士、お互いに呼び出し合いが可能な模様だ。
重要なのは、PaizaでSchemeを立ち上げる際の「Main.scm」と書かれたファイル「だけ」が下のレスポンス部分への表示を司る権利がある模様。つまり、そこがmainプログラムになる。
従って、構造的には、サブファイルでモジュールをガンガン作っていって、Main.scmからそれを呼び出せば、実行結果を見れる、と言うような仕組みになってるらしい。

Paiza上部のタブ類。+ボタンを押せば新規ファイルが生成される。それぞれにファイル名を名付けてモジュール作成し、Main.scmと言うファイルから呼び出せば実行結果が見れる。
Main.scmには例えば、上の例で言うとex17-6.scmに含まれるex17-6モジュールを実行したい場合、次のように記述すればいい。

たったの二行だけ、記述する。
一行目は、前書いた通り、Gaucheのモジュールロードパスにカレントディレクトリ(つまり、ここで言うと、Paiza上で書いたファイル群がある場所)を追加する為のオマジナイだ。
それに続いて、作成済みで実行したいモジュールをuseコマンドを使って呼び出せばいい。
別にこの通りにやらなくても構わないんだけど、単に星田さんが記述したファイルの行数が1,700行を超えてるんで(笑)、ちと大丈夫かいな、と心配になっただけ、です(笑)。
さて、残りは星田さんの疑問に答えていこう。
と言うか、かなり感心して記事を読んでた。星田さんは実験屋だ。感性が理科系なんだろうな。思いついた事を徹底して検証しようと言う才覚に恵まれてると思う。
道理で上達が早いわけだ。
さて。

各要素に関数を適用するコイツで足踏みとなる

match-lambdaを高階関数的に使うにはどうしたら良いのかが分からない・・もしかして適当に前につけたら? ま、駄目ですよねぇ

結局内部に書くしか無いのか・・これなら動くけど使い回せないじゃないか・・。fで済ましている他のところもLambdaを書かないといけないので長くなるし。ただ、考えようによってはパターンごとに自由に関数を設定できるというメリットはあるか・・
実験で相当苦労したみたいだ。
ただし、最初に言っておく。星田さんの発想は100%正しい。
ちょっとだけ、match-lambdaの性質を読み間違えてたんだ。
それで、本題に入る前にちと能書きを垂れよう。
こう、プログラミング初心者とか見ると、星田さんももうちょっとで実感するだろうけど、
「あ〜、こういう風にやりたい、ってプログラミングしてて、上手く動かないみたいだけど、発想はいいよなぁ。」
って事があるんだよ。
特にLispだと「Close!」って叫びたいトコに出くわす事があると思う(Lispやりたい、って初心者がなかなかいないのが玉に瑕なんだが・笑)。
Lispはなるたけ「人間の発想を活かそうとする」。この辺がC言語と違うんだわ。
C言語だと「発想はともかく・・・」ってどうしても否定的な感情になるんだよ。何故ならそもそもC言語って「人間の発想を活かす」ようなプログラミング言語じゃないからだ。言っちゃえば、「(あるとすれば)機械の発想のように」プログラミングしないといけない。
要するに「人間の発想」とあまりにも距離がありすぎるわけ。だから「プログラミングのアイディア上で良い発想」だとしてもそのまま活かせない為、いっつも言ってるけど、発想レベルから躾けて行って、「矯正せなアカン」って事になるんだ。
ここで言ってる「星田さんの発想がいい」ってのは、Lisp上では実行に失敗したにせよ(実行に成功すれば100点とすれば)98点くらいは獲得してる、って意味になる。これがC言語だったら0点で、「最初っからやり直して来な!」って事になっちまう。
「言語の選択」ってのはそれくらい違いがあるわけ。
もう一度言うけど、別におべんちゃら言ってるわけじゃなくって、発想が100%イイ。これはLispで言うと「ほとんど完成に近い事を考えてる」って意味になるんだ。文字通り「あとちょっとだけ足りなかったね」って言う意味だ。
さて、何故に関数sum_treeとsum_doubleは問題なく動いたのか。もちろん「動くように書いたから」ってのは当然なんだけど(笑)、tree_mapと構造上の違いは何なのか、考えてみよう。
実は前者2つは1引数関数として設計されてるんだけど、tree_mapは2引数関数だ、ってのが違いだ。極端に言うとそれがtree_mapが動かなかった原因だ。
どういう事か?それは仕様上、match-lambdaは1引数関数なんだわ。
つまり、tree_mapにはmatch-lambdaは使えない。match-lambda*の出番なんだ。
match-lambda*が形成する式は、後続する引数を全部リストとしてまとめて受け取る。そして星田さんはcase-lambdaの経験があるんで、match-lambda*もその「まとめられた引数のリスト」をその形式のままパターンマッチングにかけなきゃならない、ってのを容易に想像出来るだろう。
従って、正解はこうだ。

これが星田さんがやりたかった事だ。
自分で見てみれば「あ、確かにあともう少しだった!」って思うだろう。
※1: Gaucheのマニュアルを読むと、構造的には実はオブジェクト指向のクラスの方がレコード型より「下に」あるらしく、言い換えるとGaucheのレコード型はクラスの構文糖衣っぽいモノらしい。
多分構造体はクラスに内部変換されてる?っぽい。知らんけど。
※2: 厳密な意味で言うと、「今作ってる等価判定述語」自体で再帰してるわけではなく、大域的に設定されてるobject-equal?の親分を呼び出す、って事になる。
※3: CLOS的なシステムだと、仮に「データテーブルが存在しない」場合は、単に新しく、専用のデータテーブルを自動生成するだけ、だ。










