毎度毎度すまないが(笑)、次のようなベクタ(配列)を考えてみる。

写真はいつも通りお世話になっている(笑)、FANZA AV女優ランキングから持ってきた(笑)。いや、お世話になってる、っつったってアッチの話じゃねぇぞ(笑)。
写真は左から
の5人だ。個人的には顔では一人目の河北彩花か三人目の石川澪が好みだがその辺もどうでもいい(笑)。
仮にこの中から石川澪の写真を探したい、とする。しかし「石川澪」と言う名前はデータにない。貴方はデータが格納された順番を覚えておかないとならない。ウゲ。
朧気ながら石川澪はベクタである変数*table*の2番目に格納した事を覚えている(結構な確率でプログラミング言語は「0から数える」)。
従って、石川澪の写真を出したい場合、次のようにすればいいわけだ。

面倒臭い(笑)。
しかし、この手法にはメリットがある。一般に配列相手に要素番号で検索を試みるととにかく速い。CPUはメモリの特定の位置に直接ジャンプする能力があるんで、その機能を直接使わないにせよ、言わばIDナンバー代わりの番号でアクセスすると、データがどんな位置にあろうとすぐさま結果を返す事が可能だ。
これをランダムアクセス、と呼ぶ。
反面、欠点は、上にも見た通りに「貴方がデータを何番目に格納したか」覚えてないといけないわけだ。速い事は速いが、「あれ、AV女優の名前は知ってるけど何番目に入れたかは忘れちまったよ」と言う場合、データにアクセスするのは不可能になる。困ったモンだ。
そうすると、当然「名前によってデータを引きずり出す」方が人間の記憶に対しては有効だ、って話になる。
例えば次のような構造体を考えよう。
(struct entry (key value) #:transparent)
そして変数*table*を次のように書き換える。

このように、検索の為のキー(このケースだとAV女優の名前)とデータのペアを要素として持つ配列を、一般に連想配列と呼ぶ。
これはデータ形式、つまりデータのデザインなだけ、なんで、任意のキーからデータを返すには検索関数を書かないとならない。
例えばこの場合、次のような検索関数の定義が考えられる(※1)。
(define (lookup key data)
(call/cc
(lambda (return)
(for ((i data))
(match-let (((entry k v) i))
(when (string=? k key)
(return v)))))))

つまり、変数*table*を先頭から見ていって、構造体entryのkeyフィールドが"石川澪"と言う文字列と一致した時に、そのvalueを返す、と言う仕組みだ。
これは検索をする側には分かりやすい。
一方、「先頭から見ていく」と言うのが難点だ。例えば"河北彩花"を検索する場合は*table*の先頭に格納されている以上、すぐ見つかる。一方、"紗倉まな"を探す場合、ループして探し出す必要性があるが、*table*の4つ目に格納されている以上、"河北彩花"を探すより単純に5倍時間がかかる。
このケースだと*table*はたった長さ5の配列(ベクタ)だからいいが、仮に1,000とか10,000とか100,000もの長さの配列だったらどうなるだろう。当然後ろの方に格納されたデータ検索にかかる時間は「データ配置」に従って長くなる。
人にとっては分かりやすい「検索方式」だが、こういう弱点を持ってるアクセス形式をシーケンシャルアクセスと呼ぶ。
ランダムアクセスもシーケンシャルアクセスも一長一短だ。上の例だと「AV女優の名前」を使って検索したいけど、アクセス手法自体はランダムアクセスにしたい・・・果たして両者を上手く併合出来る方法論はないだろうか。
ここである人が考えたわけだな。
「キー(上の例だとAV女優の名前)を特定の数値に変換して、キーと値をペアにしたデータを、変換した数値をインデックスとして配列に格納する。その変換規則を使って同様に検索すれば、連想配列に対してランダムアクセス出来んじゃね?」
と。
そう、キーを特定の数値に変換し、それをインデックスとして配列へキーと値をペアにしたデータを格納し、そしてその特定の数値を使ってランダムアクセスを狙う、と言う実装方法をハッシュテーブル、と呼ぶ。
今回はハッシュテーブルの話、だ。そして実の事を言うとハッシュテーブルの闇、が今回のテーマだ。
まずはWikipediaによるハッシュテーブルの説明を読んでもらおう。多分「なるほど、ふむふむ」とはなると思う。
しかし同時に、歯に何か挟まったようなカンジも受けるんじゃなかろうか。
そう、実はそこの説明だとハッシュ関数が何なのか、その具体的な説明が一切ない、んだよな(笑)。
ここで用語をちと整理しよう。上で書いた通り、「キーを特定の数値に変換する」関数をハッシュ関数と呼ぶ。ハッシュテーブルと言う名称は、単純に言うと「ハッシュ関数を利用したテーブル(表)」って事だ(※2)。
さて、検索、って観点に戻ると、当然キーってのは「唯一無二」のブツじゃないといけない。同じキーが何個もあったら、検索対象である「値」のどれを指してるのか全くわからなくなるから、だ。
ここで「文字列」を考えてみると、文字列自体は原則重複しないんだ。辞書を考えてみれば明らかだろう。もちろん同音異義語的なモノはあり得るんだけど、その「意味」はリストで実は纏められる以上、字面である「文字列」は唯一無二になってしまう。逆に言うと、そうじゃないと「辞書」が意味を成さなくなるわけだ。
一方、数値の場合はこれも数値一つ一つは確かにユニークではあるんだ。ところが、「文字列を"ある規則に則って"整数に変換する」って事を考えてみると、本当にそれが「唯一無二」の数値になるか保証がない。いや、マジで無いんだ。
そしてこの弱点は次の事によって加速する。数字は無限で存在する。従ってこの世に存在する文字列と一対一で対応させるこたぁ理論的には可能だ。
一方、現実問題としてメモリの大きさは、工業的に増加傾向にはあるけど、有限だ。つまり、「無限にデカい数値を使って文字列と一対一対応が出来るアドレスを振り分ける」事は出来ない。また、数値がどんなに大きくても扱える、ってこたぁない。CPUだって扱える数の上限が決まってる。そして「無限に大きい数値」を演算するのも不可能だ。我々が必要なのは「計算自体も比較的すぐ」終わる事だ。そもそも、データへのアクセス時間の低減が必要だった、ってのがテーマだったのに、文字列から数値への変換が無限時間を食うようなら本末転倒も甚だしいだろう(笑)。
そうすると、ハッシュ関数に要求されてるのは、
- 完全な、とは限らないが、一つのキーに対してなるたけ一つの数値を結びつけるモノを返す
- 複雑な計算ではなく、なるたけ即時計算が終了する
の2つ、となる。
あまりに抽象的だろ(笑)?だからこそWikipediaの日本語版に、「これがハッシュ関数だ」と紹介されてないわけだ(笑)。
また1番を良く見てみよう。実は「文字列から数値をでっち上げる」際に、確率は低いにせよ、「全く同じ数値が割り当てられる」事が無いわけではない。これを衝突と表現する。与えるキーによっては頻繁にこの衝突が起こる可能性がある。
衝突が起きた場合にどうするのか、ってのは後で話すとして、いずれにせよ、ハッシュ関数とは理想論は定義されているけど具体的にこれ、と言った実装はない、ブツなんだ。言わば現実的な問題ではある種画餅だ(笑)。
今までは文字列で考えてきたけど、例えば、欧米のとあるサイトには
電話番号をキーとするハッシュテーブルを作るとして、電話番号そのものを使うよりその一部を取り出すハッシュ関数を作った方が有効です。一方、そう言った場合、電話番号の先頭数字を取るより下4桁を取るようなハッシュ関数を作った方が衝突しづらいです。
とか書いている。「電話番号の一部を取る」のもハッシュ関数の定義としては(具体的な定義がない以上・笑)有効だ。そして、確かに03を取るより下4桁の例えば4567をハッシュとした方が衝突は起きづらいだろう・・・ただし、03-123-4567の他に06-987-4567なんつー電話番号が「あったら」この2つは明らかに衝突する。
下4桁で「衝突しない」と言うのはあくまで「確率的には低いだろう」と言う事に過ぎない。
そして、プログラミング言語毎に、その実装者の好みでハッシュ関数は定義されていて、どれがどれより汎用的で有用だ、と言う話も実はない。
使う側には便利だけど、実装を考えるとかなり困る、ってのがハッシュテーブルなんだよ(笑)。
ここでは、まず最初に、上のAV女優の例で、至極簡単なハッシュテーブル実装を見てみよう。
そして「衝突回避」の問題としては、データを保持する配列(ベクタ)に一つ工夫がある。と言うのも、最も単純な文字列を数値に変換するハッシュ関数では、計算に保存先の配列の長さを利用する。具体的には配列の長さを除数として剰余計算を行うんだけど、「割る側の数」が素数であると衝突の可能性が若干減る・・・と言うのも素数は定義上「1とその数自身でしか割れない数」なわけで、「他の数で割れる」事が無い以上、安全性が増すわけだ。
従って、データを保存する側の配列の「長さ」は素数にしておく、と言うのが良く見られるテクニックだ(そのクセ、2^nに近い素数だと精度が落ちる、ってな話もあるんで正直ワケが分からない・苦笑)。
また、使用する言語がLispなのにリストを使わないのは珍しい、って思うかもしんない。それはリストがまさしくシーケンシャルアクセス前提のデータ型だからだ。よってハッシュテーブルと言うお題では適したデータ型ではない。list-refは一見リストをインデックス操作してるように見えるが、実装の実態は殆どcdr再帰だろう。よってネタ的にそぐわないんでここでは使わない。
また、ハッシュテーブル自体はそもそも破壊的変更前提の抽象データ型なんで、関数型プログラミングもクソもない、んで珍しく破壊的変更前提で話をする。
まず最初に配列(ベクタ)を用いてテーブルを設定する。大きさは取り敢えず、素数である101としてみよう。
(define *bucket* (make-vector 101 #f))
次にハッシュ関数を実装してみよう。
さて、あっちこっち見てみるとマジでハッシュ関数を「どう実装するか」については書いてない事が多い(笑)。例えば今回想定している文字列から整数への変換法にしても「変換する」とは書いてても「どのように?」は書いてなかったりする(笑)。企業秘密なのか(笑・※3)。
まずは単純な実装から考えよう。「文字列から整数へ変換する」前提なら、マジで文字をまずは整数に直してそれを全部足せばどうだ?と考える。
例えば"石川澪"と言う文字列に対しては、
> (string->list "石川澪")
'(#\石 #\川 #\澪)
と言う「文字のリスト」が手に入る。ついでにそれを全部数値情報に直すにはこうすればいい。
> (map char->integer (string->list "石川澪"))
'(30707 24029 28586)
アルファベットと違って漢字は数値がデカい(笑)。
そして総和を取れば
> (apply + (map char->integer (string->list "石川澪")))
83322
となる。
こういうカンジで文字列から数値を生成し、それをハッシュテーブル*bucket*の大きさで割った余りをハッシュ関数の返り値とする。
この発想でハッシュ関数を書くと、こうなる。
(define (hash s)
(modulo (apply + (map char->integer (string->list s)))
(vector-length *bucket*)))
試してみよう。
> (hash "河北彩花")
21
> (hash "五条恋")
27
> (hash "石川澪")
98
> (hash "桜空もも")
86
> (hash "紗倉まな")
55
確かにこのケースだと、各AV女優の名前に従って別々の数値が割り当てられている。
また、「AV女優の名前」とハッシュ関数が返す値の大小が全く関係がない、ってのも見れば分かると思う。結果、ハッシュテーブルへの「登録順」と、「どこに格納されるか」は一致していない。これが一般に、ハッシュテーブルのキーや値の並びが「順不同」になってる原因だ(※4)。
なおこの計算法だと、「いつでも」このように別々の値が振り分けられるのか、と言われると「違う」のは想像に難くないだろう。例えばこの方式だと、いわゆるアナグラムには弱い。
> (hash "silent")
49
> (hash "listen")
49
"silent"と"listen"は意味は全く違うが、一方、文字列に含まれる文字自体は位置が違っても種類も個数も全く同じなので同じハッシュ値を返してしまう。要は衝突が起こるわけだな。
もっと「良い」ハッシュ関数はあるのか。その辺は後回しにしておいて、取り敢えず基本的なハッシュテーブルの実装方法に付いて話を進めよう。
ハッシュテーブルにキーと値を登録する関数insertはvector-set!を使えば次のように簡単に書く事が出来る。
(define (insert key val)
(vector-set! *bucket* (hash key) (entry key val)))

長くなるから表示せんが(笑)、"石川澪"と言うキーと写真のペアは長さ101の配列(ベクタ)*bucket*の(hash関数が計算した)98番目の要素として格納される。
また、ハッシュ関数を使えば、配列(ベクタ)から「ランダムアクセス」として要素を引っこ抜いてくるのも簡単に書ける。
(define (lookup key)
(let ((elm (vector-ref *bucket* (hash key))))
(and elm (entry-value elm))))

検索関数が簡単に書ける以上、削除関数も簡単に書ける。
(define (delete key)
(vector-set! *bucket* (hash key) #f))

ハッシュ関数さえ書ければいわゆるハッシュテーブルを書く事自体はさして難しい作業じゃない、って事が分かるだろう。
ところで、ここで疑問に思うかもしんない。今、いわゆる「連想配列」の形式でハッシュテーブルを実装した。ハッシュテーブルへのアクセスはどのみちハッシュ関数を使用している。
しかし、このように「ハッシュ関数を使った」アクセスをしている以上、果たして連想配列、要はキーとペアのカタチで配列にデータを記録する必要があるのか?単なる配列相手でも構わないんじゃないか、と言う疑問だ。
実の事を言うと、理論的にはその通り、だ。ハッシュ関数だけがあれば、キーの情報自体はデータに含めなくて構わない筈だ。
しかしながら、先にも書いた通り、ハッシュ関数は不完全なんだ。文字列であるキーを数値に変換してもそれがユニークである保証がない。僕らが書けるのは「ユニークに限りなく近い」数値をでっち上げるだけ、で場合によってはキーは簡単に衝突する。そして衝突した際に安全策としてデータ側に既存のキーを「記録」してるんだ。
ここで次のようにプログラムを修正してみる。今現在ハッシュテーブルは101の長さを持つ配列とした。
これをAV女優5人分を登録したらフルになる、と言う前提として5つしかデータを取れないハッシュテーブルを考えよう。5は素数なんで一見問題が無いように見える。
しかしこの状態でハッシュ関数を走らせると次のようになるんだ。
> (hash "河北彩花")
0
> (hash "五条恋")
2
> (hash "石川澪")
2
> (hash "桜空もも")
1
> (hash "紗倉まな")
0
>
途端にキーが衝突しだすのが分かるだろうか。これは後に紹介する「より良いハッシュ関数」でも変わらない。配列(ベクタ)のサイズがデータ数ギリギリまで小さいと途端に衝突する率が高まる。
ちょっと実験してみよう。5人のAV女優に対して7つ(つまり、5の次の素数)の要素を持った配列(ベクタ)を用意する。それに対してハッシュ関数の計算結果は次のようになる。
> (hash "河北彩花")
6
> (hash "五条恋")
0
> (hash "石川澪")
1
> (hash "桜空もも")
5
> (hash "紗倉まな")
5
衝突の率は減ったが、それでも"桜空もも"と"紗倉まな"のキーは衝突している。
では、7の次の素数、11個の要素を持てる配列(ベクタ)に対してはどうだろうか。
> (hash "河北彩花")
5
> (hash "五条恋")
7
> (hash "石川澪")
8
> (hash "桜空もも")
10
> (hash "紗倉まな")
1
今度は衝突は辛うじて起きていない。
実は経験則的に一般には、ハッシュテーブルに登録されたデータ数が配列(ベクタ)の要素数の80%を超えると、途端に頻繁にキーが衝突する事が知られている。
上の実験だと5人のAV女優に対して7つの要素数、って事は71%程要素を埋めてるので、衝突が起きる率が高まってる。一方、11の要素数、って事は45%。まだ半分埋まってないわけだ。だから衝突確率はまだ低い。
と言うわけで、一般のハッシュテーブルの場合、上で書いたように、例えば80%をしきい値にしておいて、データ数が配列の要素数の80%辺りになると「より大きな配列を用意」して、既存のハッシュテーブルに登録されたキーに対してハッシュ関数を再計算し、そしてキーと値のペアを新しいハッシュテーブルへと移す。これをリハッシュと呼んだりする。
当然、リハッシュする以上、元々のキーのデータが無ければならない。大きくした配列に対するハッシュ値の計算は、計算に配列のサイズを使ってる以上、以前の計算結果と違ってくるわけだ。
いずれにせよ、思ったよりハッシュ関数が安定してない、っつーか「信用ならん」事が分かるだろう(笑)。保険の意味でも、キーは保存しとかなきゃならないんだ。
では衝突が起きた場合はどうするのか。
上でのinsertなんかの実装では、関数側では一旦数値に直す以上、「元のキーが何だったのか」は感知しない。従って、例えば"silent"をキーとしてるデータに対して"listen"をキーとしたデータが「書き換えてしまう」事はあり得る。これはあまり嬉しくないだろう。
一つの解決策は、衝突が起きたキーの近傍で空いてるスペースに衝突が起きたペアを挿入する事。ハッシュ関数の二重掛け、三重掛け、四重掛け、等を行いつつ、適正な場所を選び出す手法だ。
今回はこれは扱わない。
もう一つの方法は、配列の要素をリストにしてしまう事だ。衝突が起きてもリストなら、衝突したデータを簡単に追加可能だ。
今回はRacketと言うLispを使うんで、この方式で実装する。
すなわち、テーブルとする配列(ベクタ)*bucket*を
(define *bucket* (make-vector 5 '()))
のように定義し、関数lookup、delete、insertを次のように定義し直す。
(define (lookup bucket key)
(let ((lst (vector-ref bucket (hash key))))
(if (null? lst)
#f
(entry-value
(car
(member key lst
(lambda (x y)
(string=? x (entry-key y)))))))))
(define (delete bucket key)
(vector-set! bucket (hash key)
(remove key
(vector-ref bucket (hash key))
(lambda (x y)
(string=? x (entry-key y))))))
(define (insert bucket key value)
(delete bucket key)
(vector-set! bucket (hash key)
(cons (entry key value) (vector-ref bucket (hash key)))))
今度の関数lookup、delete、insertは引数に対象とする配列(ベクタ)を取るようになってて、先程の関数lookup、delete、insertとは大幅に見た目が違う。
が、騙されるな。基本ロジックは以前に書いた関数lookup、delete、insertと全く同じだ。ただし、テーブル(*bucket*)の要素が今度はリストになってるので、その中にアクセスする手順が追加されてるだけ、だ。
原則、ハッシュ関数で選ばれたテーブルの要素(リスト)にキーと値のペアをconsしていく、ってのがアイディアだ。結果、検索関数lookupはハッシュ関数で指定された要素のリストからmemberで目的としたペアを先頭としたリストを得る。先頭が目標データなんでcarしてそこからentry-valueを得て返す。
同様にdeleteも結果、リスト対象の操作になる。ハッシュ関数で指定された要素(リスト)からキーに該当するデータをremoveしてテーブルを書き換える。
関数insertは最初に、キーで指定されたデータをハッシュ関数で指定された要素(リスト)内から削除しておく。と言うのも、ここはconsするのが目的で、同じキーを持ったデータが要素内にあれば削除しといた方がベターだからだ。無ければ無いで影響は出ないんで問題がない。
結果、AV女優5人を使うと5要素しかないテーブル(*bucket*)は次のようになる。


*bucket*の第0要素には紗倉まなと河北彩花の二人が、第1要素には桜空もも、第2要素には石川澪と五条恋の二人がマッピングされて、第3要素と第4要素は「空き」になってるのが分かるだろう。
そして検索に対しては、次のようにキチンとターゲットを返してくれる。

機能的にはこの通りになる、って納得するだろう。
一方、ここで「衝突したキーを持ったデータ」をリストに格納する、と言う事に付いて疑問に感じる人もいるんじゃないか。
「リストってシーケンシャルアクセスなんでしょ?じゃあ、ハッシュ関数を使って配列要素を確定したにしても、その後リストを先頭から見ていく、ってぇのなら意味がないんじゃない?」
それは全くその通り、なんだ。
言い換えると、キーの衝突が増えるとハッシュテーブルは劇的に性能が落ちる、と言う事が良く知られている。
実はそれを回避する為、もあって、しきい値を設定しておいて、その付近に格納データ数が近づいてくるとリハッシュする、って仕組みになってるわけ。
もう一回要点を整理しよう。ハッシュテーブルの性能低下を避けるには、
- 想定するデータ数に対して十二分なメモリ領域(具体的には配列サイズ)を用意する。
- 衝突が起こりづらいハッシュ関数を用いる。
の2点が肝要なんだ。1.が要請してるのは、「用意されたハッシュテーブルの全要素を使い切る事はない」と言う事だ。結局、保持してるデータ数がハッシュテーブルを埋め尽くす前に、より大きなハッシュテーブルを生成して、そこに全データを移し替えないとハッシュテーブルは使い物にならない、と言った事を表している。
なお、アルゴリズムの本によっては、衝突時に備えてリストを使う代わりに二分探索木を使う、と言うような方法を使ってる場合がある。
ただし、個人的な意見ではそれは無駄だ(笑)。っつーか二分探索木は二分探索木として使うべきだ。
二分探索木は未来の標準抽象データ型だ。発想は簡単だし、カタログスペック的にはハッシュテーブルより検索速度は落ちるが、平均的には高速だ。実装に関してはハッシュテーブルに比べるとデータの追加・削除に手間はかかるが一方、キーの衝突、なんつー現象がない。
いずれにせよ、ハッシュテーブルに於ける「キーの衝突」に対して、高速化を理由に、直接競合するようなデータ型を導入する必要はないだろう。「キーが衝突している状態」で、その衝突してるデータの検索高速性を図るよか、さっさとリハッシュした方がいいと思う。
残るネタは二番だ。「より良いハッシュ関数でどんなモノが考えられるか」。
「プログラミング言語C」の著者、カーニハンとリッチーはこんなハッシュ関数を紹介(※5)していて、恐らく世界で最も有名なハッシュ関数だろう。
 | プログラミング言語C 第2版 ANSI規格準拠 B.W.カーニハン 共立出版 |
ここで紹介されているハッシュ関数は数理的には次のような事を意図してる(hashvalの初期値は0とする)。

当然プログラミングではこんな漸化式を解く必要はない。Racketではfoldlを使って書けば次のようになる。
(define (hash s)
(modulo
(foldl (lambda (y x)
(+ y (* 31 x))) 0 (map char->integer (string->list s)))
(vector-length *bucket*)))
これが「どの程度良い」ハッシュ関数なのかは正直言うと知らない(笑)。でも恐らく、「もっとも使われている」ハッシュ関数じゃないか、と思われる。なぜなら「プログラミング言語C」と言う書籍が売れまくったから、だ。
他には、次のようなハッシュ関数も推薦されている。
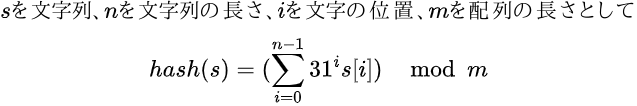
(define (hash s)
(modulo
(apply +
(map (match-lambda
(`(,a ,p)
(* a p)))
(zip (unfold (lambda (x)
(> x (string-length s)))
(lambda (x)
(expt 31 x))
add1
0)
(map char->integer (string->list s)))))
(vector-length *bucket*)))
これは色々と書き方が考えられるので、例えば次のように書いてもいいだろう。
(define (hash s)
(let ((s (map char->integer (string->list s))))
(modulo
(apply +
(map (lambda (i s)
(* (expt 31 i) s))
(range (length s))
s))
(vector-length *bucket*))))
いずれにせよ、これら2つが「良く使われる」ハッシュ関数となる。
ところで、31って何なのか気になるだろ?
欧米のサイトでは次のような書かれ方をしてるのが散見される。
例えばアルファベットは26文字なんで、小文字だけを使うなら、近い素数31を使うと衝突を避けられる良いハッシュ値が求まります。大文字も使うなら53等が適当でしょう。
ところが、この理由付けは明らかにおかしい(笑)。そもそも素数列を見ると、
2, 3, 5, 7, 11, 13, 17, 19, 23, 29, 31, 37,...
なんでアルファベットの小文字だけ使うとしても29を選択肢にせず、31を選択肢にする理由が見つからないんだ(笑)。
しかも大文字を含めると・・・と言う議論もヘンだ。
じゃあ日本語はどうなる?恐らくコンピュータ上で扱える日本語の文字は2万に行くか行かないか、ってトコだろう。そう、我々は総数が2万もある文字を操ってる民族なんだ(笑)。
で、だ。上の議論をまともに受け取ると、日本語でハッシュ関数を作ると31じゃなくて、最低でも2万超えで一番小さい素数20,011を使わないとならない。そして上の「一般的に良いと思われてる」ハッシュ関数の計算式を見てみろ。素数を二乗したり三乗したり・・・20,011を代入したらどうなる(笑)?天文学的な大きさの数値に膨れ上がってとてもじゃねぇけど「使いモンにならん」だろ(笑)。
だとすれば、「ハッシュ関数は英語だけにとって使える手法」って事になる。差別だ(笑)。ポリティカル・コレクトネスで見ると「正しくない」関数だ(笑)。
いや、当然んなバカな事はあり得なくって、現に、UTF-8を広めたJavaのハッシュマップもソースコードには31が含まれてるらしい。じゃあ、素数として何故に31を選んだのか、と言うのは「別の理由が無ければならない」。
ちなみに、話に依ると「プログラミング言語C」を書いたカーニハン&リッチーも「何故に31を使うのか」その理由は知らなかったらしい(笑)。同書は別にアルゴリズムの本ではないんで、「ハッシュテーブルに関する実装に関するアレコレ」に付いては全く解説してないんだけど、そもそも「昔からこうしてるからこうしてる」んで書いてる、って話だ(笑)。
だから言ったろ(笑)?別にプログラマはそこまで「理論的」じゃないんだよ(笑)。人に説教する時には「キチンと自分で考えて・・・」とか言うけど、実は自分は考えてない、んだ(笑)。
言っちゃえば彼らが言う「理屈」なんてこの程度だ。
弟子: 「師匠!師匠の揚げる天ぷらはサイコーです!どうしてこんなに旨いんですか?」師匠: 「それはな、伝統だからだ!」弟子: 「素晴らしい論理です!」
こんなもん、論理でもクソでもないんだが(笑)、プログラマはこの程度の事しか言わなかったりするし、それを「理屈」だと思い込んでる。
彼らの発想はどっちかっつーと「理論屋」より職人の方に近いんだ。
実は31は素数なんだけど、メルセンヌ素数と呼ばれる特殊な素数だ。これは素数のうち、

で書き表されるモノを指す。・・・・・・勘がいい人なら気づくだろうけど、2の累乗を基礎としてる、って事はビット演算がしやすいんだ。シフト演算と呼ばれる計算法はCPUが最も得意かつ高速で行える手法だ。
恐らくかつてのミニコンの、現実的に計算対象として扱えるメルセンヌ素数の最大値だったんじゃないか。31×何か、は何かを5回左シフトした後何かを引く、だけでいい。ハードウェアの仕様にも依るけど、恐らくハッシュテーブルが開発された当時だと、この辺がギリギリ許容出来る「計算方法」だったんじゃないか。
一方、31より大きいメルセンヌ素数は127になる。これはホンマ、現在の8bit単位のメモリでもパーツ一個とすればギリギリだ。7回左シフトってのはそういう意味になる。かつてのミニコンでも、メモリの境界線ギリギリだったんで、採用出来なかったんだろう。
なお、とある研究では、50,000以上の英単語を31を使った多項式ローリングハッシュ関数で調べてみたら衝突するのは7つ以下だった、と言う話がある。また、次のメルセンヌ素数127を用いたらもっと衝突率が下がる、と言う話もある。個人的に確かめたわけではないが、英語を考えると、実用的には31で充分、と言う判断なんだろう・・・・・・誰か日本語でこういう研究してくれないもんだか(笑)。
良くある、ハッシュテーブルから全キーのリスト及び全値のリストを返す関数を書くのも、ここまでのハッシュテーブルの仕組みを理解すれば特に難しくはない。
(define (getkeys bucket)
(flatten
(vector->list
(vector-map (lambda (x)
(map entry-key x)) bucket))))
(define (getvalues bucket)
(flatten
(vector->list
(vector-map (lambda (x)
(map entry-value x)) bucket))))
殆ど瓜二つの関数だ(当たり前だが)。

繰り返すが、データの追加順と格納順は関係ない。ハッシュ関数が「挿入位置を決める」からだ。
一方、この実装の場合、entryと言う構造体にキーと値を詰め込んでるんで、キーと値の位置関係は同じになる。
上のキーのリストや値のリストを返す関数を書ければ、リハッシュ関数を書く事も易しいと思える。詳細は省くが、素数列をデータとして持っておけば、現在のハッシュテーブルに於ける保持データが配列の、設定されたしきい値を越えた時点で、リハッシュするようなプログラムを書けばいい。大体現在のハッシュテーブルのサイズの二倍より大きい素数をサイズとして設定しておけばいい筈なんだ。
ところが、ここで一つ問題がある。リハッシュとは大域的に設定された配列*bucket*に対して行うモノとなる。しかし、毎回毎回同じ大域変数名でいいのか。当然プログラムする側からすると、ハッシュテーブルを設定する際に「好みの名前」を付けたくなるだろう。
一方、今までの通り、関数としてリハッシュを引数で大域変数名を取っても、大域変数自体の配列をすげ替える事が出来ないんだ。なぜなら、Racketは厳密にスコープを取るので、配列要素を破壊的変更する事は出来るが、配列そのものを破壊的変更は出来ない。
> (define x 'foo)
> (define (hoge x) (set! x 'bar))
> (hoge x) ; 大域変数xを変更したつもりでも、xは大域変数のコピーになる
> x
'foo
これじゃアカン。
じゃあどうすればいいのか。ここで「オブジェクト指向の理論的な枠組み」が応用出来る。オブジェクト指向の「仕組み」はあくまで理論的なモノだが、一方、ハッシュテーブルはその「理論」を現実に応用出来るレアケースになる。

ちと分かりづらいかもしれんが、最初はわざと要素数が2個しかないハッシュテーブルを定義し、そこにデータを追加していき、データ個数が配列の要素数の80%を越えた時点で配列が初期の2の2倍を超える最初の素数、5の要素数を持った配列へとすげ替えられ、ハッシュ関数の計算がやり直されてどこにどのデータが収まるか、も変わっている。
なお、この実装では、メッセージ送信を利用して外部的に新しく操作関数を定義する方針で書かれている。そのテクニックは今まで使った事は無いが、今後紹介するかもしんない。
いずれにせよ、これでハッシュテーブルの実装は終了だ。
お疲れ様。
ただし、Racketのforは本当に副作用目的で返り値がない。かつ、Racketは明示的なreturnを持たない為、call/ccでreturnを持って脱出する、と言うRacketとしてはあまり褒められたモノではないコードとなっている。
(define (lookup key data)
(call/cc
(lambda (return)
(dotimes (n (vector-length data) n)
(match-let (((entry k v) (vector-ref data n)))
(when (string=? k key)
(return v)))))))
また、よりティピカルにSchemeらしく書きたい場合は、SRFI-43のvector-for-eachを使っても良いだろう。
(define (lookup key data)
(call/cc
(lambda (return)
(vector-for-each (match-lambda*
(`(,i ,(entry k v))
(when (string=? k key)
(return v)))) data))))
いずれにせよ、「条件に見合った時に計算を止めて脱出する」為にcall/ccのお世話になるんで、call/ccの練習としても良いだろう。
※2: ハッシュはマクドナルドで売ってる「ハッシュポテト」のハッシュと全く同じ単語で、意味は「切り刻む」とか「刻みまくる」と言うモノ。

以前にも書いたが、ハッシュテーブルはコンピュータの歴史での登場は極めて早く、1953年辺りには既に開発されている、プログラミング上では最古の抽象データ構造の一つ、と言って良い。Lispの基となる線形連結リストの登場が1955年から1956年にかけて、って辺りを見てもその古さは際立つだろう(要は、実はハッシュテーブルはリストよりも古い、ってこった)。
なお、当初からハッシュテーブルと呼ばれてたわけじゃなく、いつの間にか例によって、バズワードである「ハッシュ」が定着したようだ。恐らく1980年代中頃にはハッシュテーブルやハッシュ関数と言った言い回しが広まってたようだ。
なお、バズワードだった「ハッシング」と言う言い回しを書籍で定着させた人物が実は、ポール・グレアムがちょくちょく引き合いに出す、友人でViawebの共同創設者かつLisp方言Arcの開発者の一人であるロバート・モリスの父親らしい。
※3: ハッシュテーブルは元々IBMで生まれた。
※4: 最近のPythonでは順序は保全されるようになったが(どうしてそうなってんのかは知らんが・笑)、一般的にはハッシュテーブルのキーや値の並びは一見「意味不明」になってる。
※5: C99以降で望ましい、と思われるスタイルへと書き直している。