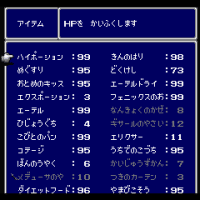
星田さんの記事に対するコメント。
今回は1点。付属に「提案として」1点ある。
っつーかあまり気にせんように。
「あ〜、そろそろ出会って一年か」とか言う話を思い出すと、圧倒的に星田さんはパワーアップしてる。
昨年書いたプログラムを今Lispで書けば、「難なく書き終えられる」くらいに進化してる。ただの人間からLispエイリアンへ、だ(謎
 参考: Lispエイリアン
参考: Lispエイリアンまぁ、こんな人外になりたいかどうかはさておいて、だ(謎
1点目。

まずは思ったようにプログラムが動いた事を喜ぼう。
モックアップとしては大性交成功だ。
ただ、気づいただろうか?
実は[0:持ち物を見る]は文字列の出力なんだけど、以降はリストで出力されている。
つまり、出力の形式が途中から変わってるんだ(気づきづらいがカッコに注目!)。
文字列出力のキモ、ってのはある意味形式を整える事だ。
つまり、全形式を揃えておきたい、となるだろう。
ポイントは、map以降でリストを生成してるトコだ。
(map (match-lambda (`(,index . ,id)
(format "[~a:~a 銀貨~a枚]"
index
(item-name id)
(item-cost id))))
(enumerate (page-lst page)))
平たく言うと、これが文字列のリストなんで、文字列[0:持ち物を見る]をconsしちまえばいい。
(cons "[0:持ち物を見る]" (map (match-lambda (`(,index . ,id)
(format "[~a:~a 銀貨~a枚]"
index
(item-name id)
(item-cost id))))
(enumerate (page-lst page))))
(for-each display
(cons "[0:持ち物を見る]" (map (match-lambda (`(,index . ,id)
(format "[~a:~a 銀貨~a枚]"
index
(item-name id)
(item-cost id))))
(enumerate (page-lst page)))))
機能的にはfor-eachとmapは変わらない。for-eachは単に、第一引数として受け取る関数が返り値がない副作用目的のもの、ってのが条件なだけだ。
そしてdisplayには返り値がない、ってのがその条件に合っている。
言い換えると、作用としては、理論的に、別にmapを使っても構わない。
(map display
(cons "[0:持ち物を見る]" (map (match-lambda (`(,index . ,id)
(format "[~a:~a 銀貨~a枚]"
index
(item-name id)
(item-cost id))))
(enumerate (page-lst page)))))
この2つの違いは、まずはfor-each自体が返り値を持たない。
一方、mapはリストとしての返り値を持つし、「計算結果をそのリストに詰め込む」性質上、「返り値の無い関数」の「計算結果」を詰め込むハメになってしまう。
Racketだと「返り値が無い」事は#<void>と表現されるんで、結果、上のmap版は
'(#<void> #<void> #<void> #<void> ...)
と言うあまり意味の無い返り値を返してしまうんだな(これは別にバグじゃなく、ある意味「想定通り」の動作だ)。
これを許容するか、せんのか、ってのはハッキリ言って趣味の問題なんだけど、一応通常パターンでは、こういう場合はfor-eachを使って無意味な返り値を避ける、ってのが無難だ。
結果、僕だったら、関数show-zaikoを次のように書く。
(define (show-zaiko page)
(for-each display
(cons "[0:持ち物を見る]" (map (match-lambda (`(,index . ,id)
(format "[~a:~a 銀貨~a枚]"
index
(item-name id)
(item-cost id))))
(enumerate (page-lst page)))))
page)
返り値に引数で貰ったpageをそのまま返してる。
コンピュータサイエンス上だと、実質、何もしてない関数って事になるんだが構わない。ひょっとしたら、あとで何かに使い回せるかもしれんから、だ。
どっちにせよ、あとで「要らない」となった場合、1シンボルを削るなんつーのは大した手間でもない。
従って「今のトコ何の役に経つか知らんが、取り敢えず貰った引数をそのまま返しておけ」と言うのはANSI Common Lispの設計が教えてくれたやっつけ仕事になる。が、意外とバカには出来ない。
一応、このテの値を返さない筈の自作出力関数では、最後に貰った引数をそのまま返すのがセオリー、って事にしておこう。
次。提案だな。

多分、僕が昨夜、ブログの記事を書いてる最中にこれを作ってて、言っちゃえば間に合わなかったんだろう。
別にこのプログラムが間違ってる、って言いたいわけじゃない。むしろ目的にはドンピシャなんだと思う。
従って、ここから書くモノはあくまで「考え方」であり、同時に特有の弱点を含んでる。
つまり、星田さんが「どうしたいのか」と言うのが一番重要になる、って話だ。
まず、恐らく*equip*と言うデータは次のような連想リストになってるんだろう。

そしてこのデータをイジる為に関数equip-changeがある(と思う)。
(define (equip-change lst index num)
(match-let ((`(,index . ,val) (assoc index lst)))
(alist-cons index (+ num val) (alist-delete index lst))))
これを使うと、次のような結果が得られる。


確かに要求仕様を満たしてるとは言える。
ただし、気づくだろうが、連想リストのアイテムの順番が変わってるんだ(笑)。
実は連想リストは構造的には、「データ追加」は常に連想リストの先頭になされる、と言う性質がある(※1)。これを是と取るか、否と取るか、ってのは大きいだろう。
僕だったら「構わん」って判断するけど、結局星田さんが、変数*equip*のデータ順序を重要と考えるか否か、ってのがキモになる。
故に、データ順序が重要なら
- やっぱり自作関数を使う
- ソートをかけられる何らかの構造を考える
のどっちかを行う、と言う事になるだろう。
仮に後者を行うのなら、以前星田さんがやろうとしてた、IDナンバーをふる、ってのがもっとも現実的な解決策になるんじゃないか。
つまり、例えば*equip*をこう設計しなおして、
(define *new-equip*
(map (match-lambda
(`(,num ,item . ,val)
`(,item ,(format "I~a" (~a num
#:align 'right
#:width 3
#:pad-string "0")) ,val)))
(enumerate *equip* 1)))

関数equip-changeをこうする。
(define (equip-change lst index num)
(match-let ((`(,index ,id ,val) (assoc index lst)))
(sort (alist-cons index `(,id ,(+ num val)) (alist-delete index lst))
string<?
#:key second)))
そうすると、IDナンバーで常にソーティングされるんで、結果、連想リストの順序は揺るがない。


まぁ、結果、星田さんの好みで、どう実装してもいいんだけど、一応、連想リストの根底の性質、ってのには注目して欲しいな、と言うお話でした(※2)。
※1: しかも原理的には元々、連想リスト、と言うデータ形式は、「データの追加」はあっても「データの削除」が無い形式なんだ。
つまり、仮にキーが重複してたとしたら、常に先に見つかったデータを返すだけで、あとにある重複データは知らんぷりだ、ってのが連想リストと言うデータ形式なんだ。
従って、元々は、「データの変更」が起こる度に、連想リストの長さはどんどん長くなっていく。現代的な観点だと「凄く無駄が多い」形式だ。
なんでこんな形式なのか?と言うと「履歴が残るから」と言うのが答えだ。「変更履歴が蓄積していく」以上、あとで「何が起こったのか」データを見直してみれば一目瞭然、と言うことになる。プログラミングしている最中に問題が生じたトコがすぐ閲覧可能で、これが黎明期の人工知能開発の助けになっていたのは間違いない。
無駄がある、と言っても、贅沢だけど「必要な」無駄だったんだ。
さすがにそれじゃ今だとアレなんで、SRFI-1は便利なalist-deleteと言う関数を用意している。これも非破壊的な関数で、指定されたキーを持ったデータを削除した連想リストを返す。
故に、alist-consとalist-deleteの組み合わせは、現代的な「データ更新」を司る機能を形作る。
※2: ちなみに、最近のPythonだと変わったらしいが、元々辞書/ハッシュテーブル内での「データの並び方」も、実装上、「順序は不明」と考えて良い。ハッシュテーブルも「検索のしやすさ」を一義としてデザインされてるので、データの並びが、こっちが考える「整列したもの」になってる保証がないんだ。
こういうデータテーブル系の「並び」は検索速度第一、で我々の感覚での「整然としてる」とは限らない、と言う事を覚えておこう。
じゃないと、とんでもないトコでハマる可能性は常にある。