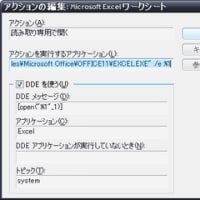
自分が設計したわけではないのですが、“あるシステム”のテーブル設計はこんな感じになっています。(ちなみにDBMS=PostgreSQL)
CREATE TABLE m_shouhin
(
interid serial NOT NULL,
shouhin_code character varying(8) NOT NULL,
eda_code numeric(2) NOT NULL,
shouhin_name character varying(20),
…
CONSTRAINT m_shouhin_pkey PRIMARY KEY (interid),
CONSTRAINT m_shouhin_unqidx UNIQUE (shouhin_code, eda_code)
)
プライマリーキーは、データとは関連のない(意味の無い)連番にして、データとして意味のある部分は一意制約とするルールのようです。
ケチをつける訳ではないですが、この「無意味な連番をプライマリーキーにする」ってどう使って欲しいのでしょう。
やりたいことはきっと、レコードを更新する際にUPDATEのWHERE句が短くなるからかな??と予想。ある程度以上のデータ数になった場合、きっとWHERE interid=~と記述すれば最速だろうと思います。
開発も終盤となってきましたが、そのような記述はシステムの中でもごくごく一部のようです。(一部=私が意図的に使ったのみ)
以前私の作った小さなシステムでも連番使いました。MS-Accessで「オートナンバー」などという機能があり、使ってみました。
そこでは、「発行番号」という、本当に意味の無いただの連番が欲しかったので、そのままプライマリーキーとして利用。マッチしていました。
しかし“あるシステム”では、もれなくinteridがプライマリーキー、別の(データとして意味のある)フィールドが一意制約+NOT NULL制約になっています。
一意制約+NOT NULL制約 = プライマリーキー制約なのに…
PostgreSQLではUNIQUE制約はインデックスも作成される実装のようなので、パフォーマンス的には問題にならないのかもしれませんが。
全テーブルについている使えないinteridが正直目障り。あ、結局ケチつけちゃった。
CREATE TABLE m_shouhin
(
interid serial NOT NULL,
shouhin_code character varying(8) NOT NULL,
eda_code numeric(2) NOT NULL,
shouhin_name character varying(20),
…
CONSTRAINT m_shouhin_pkey PRIMARY KEY (interid),
CONSTRAINT m_shouhin_unqidx UNIQUE (shouhin_code, eda_code)
)
プライマリーキーは、データとは関連のない(意味の無い)連番にして、データとして意味のある部分は一意制約とするルールのようです。
ケチをつける訳ではないですが、この「無意味な連番をプライマリーキーにする」ってどう使って欲しいのでしょう。
やりたいことはきっと、レコードを更新する際にUPDATEのWHERE句が短くなるからかな??と予想。ある程度以上のデータ数になった場合、きっとWHERE interid=~と記述すれば最速だろうと思います。
開発も終盤となってきましたが、そのような記述はシステムの中でもごくごく一部のようです。(一部=私が意図的に使ったのみ)
以前私の作った小さなシステムでも連番使いました。MS-Accessで「オートナンバー」などという機能があり、使ってみました。
そこでは、「発行番号」という、本当に意味の無いただの連番が欲しかったので、そのままプライマリーキーとして利用。マッチしていました。
しかし“あるシステム”では、もれなくinteridがプライマリーキー、別の(データとして意味のある)フィールドが一意制約+NOT NULL制約になっています。
一意制約+NOT NULL制約 = プライマリーキー制約なのに…
PostgreSQLではUNIQUE制約はインデックスも作成される実装のようなので、パフォーマンス的には問題にならないのかもしれませんが。
全テーブルについている使えないinteridが正直目障り。あ、結局ケチつけちゃった。