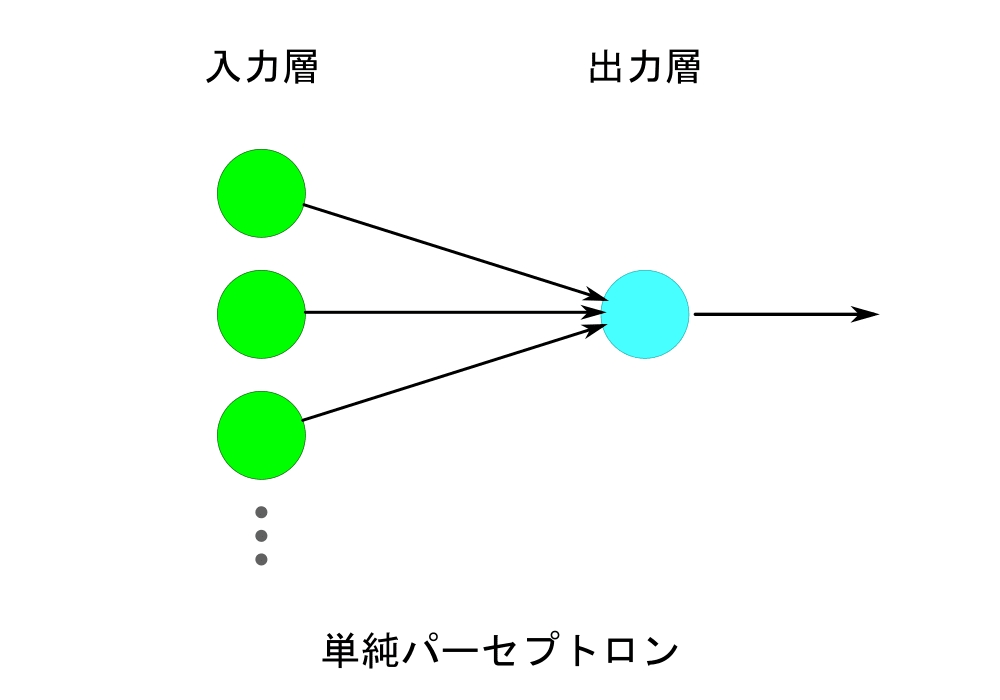
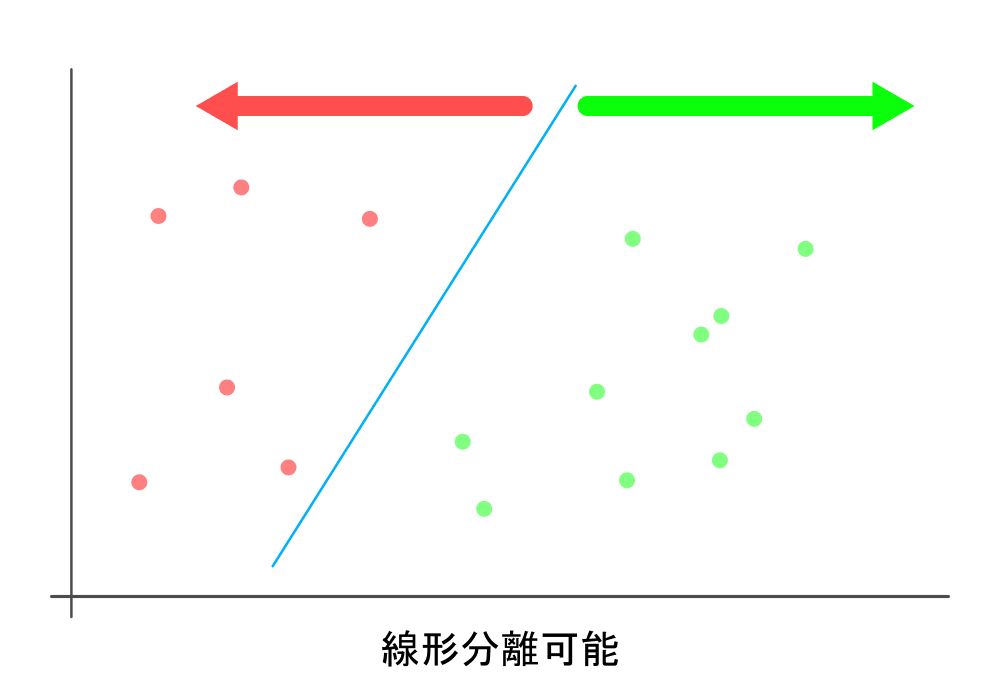
前回はOpenFaceという顔認識に特化したディープラーニングライブラリを紹介させていただきました。
今回は実際にOpenFaceをインストールして、リアルタイムな顔認識デモを動かすまでの流れを解説したいと思います。ある程度Linuxの知識がある人を対象に書いています。
※試す際には、WebカメラとPCをご用意ください。
下記の流れで解説します。
1. Ubuntu仮想マシンの作成
2. OpenFaceおよび必要なソフトウェアのインストール
3. 動かしてみよう
※手順1と2はDockerを使うことでスキップできるようです。詳しくはこちら。
Dockerだと中身に触りづらいため、今回は自力でセットアップします。
具体的な解説に入る前に・・・今回使用したPCはこんな構成です。
・OS … Windows 7 Professional 64bit
・CPU … Core i5 3230M (2コア4スレッド)
・メインメモリ … 12GB
・ストレージ … SSD
※2013年代に発売したノートPCです。
--------
1. Ubuntu仮想マシンの作成
まずは動作環境を構築します。今回はVMWare Workstation Playerの仮想マシンにUbuntuをインストールして使用します。(VMWare Workstation Playerは個人利用の場合のみ無料で使える仮想マシン環境です。この記事ではすでにインストールされているものとします。)
ここから「Ubuntu 16.04 LTS 64bit版」のOSイメージファイルを取得してください。(2017年3月現在では「ubuntu-ja-16.04-desktop-amd64.iso」というファイルがダウンロードできました。)
ダウンロードしたら、そのOSイメージファイルを使ってVMWare Workstation Playerで新規VMをセットアップしてください。パワーオン後、自動的にOSがインストールされます。
セットアップ時のハードウェア構成では下図のようにハードディスク容量を40GB以上に設定してください。(初期容量でも足りますが、念のためです。)

ユーザ名やパスワード等を設定しつつOSのインストールが完了すると、自動的に再起動してログイン画面が表示されます。そのままログインして、ソフトウェアアップデートをしましょう。弊社ではアップデート完了まで20~30分ほど時間がかかりました。

アップデートが終わったら、再起動してください。
2. OpenFaceおよび必要なソフトウェアのインストール
次に、OpenFace本体とOpenFaceの動作に必要なソフトウェアをインストールします。端末アプリを起動してください。
端末アプリが起動したら、下記のコマンドを順に実行してください。長いですが、すべて必要なソフトウェアです。こちらも時間がかかります。弊社では全て実行し終わるまで1時間30分ほどかかりました。
※入力が必要なコマンドが混ざっていますので、一括実行は避けてください。
---- ここから ----
# aptパッケージの更新
sudo apt update
sudo apt upgrade
# 必要な apt パッケージのインストール
sudo apt install python-setuptools python-pip liblapack-dev libatlas-base-dev gfortran g++ build-essential libgtk2.0-dev libjpeg-dev libtiff5-dev libjasper-dev libopenexr-dev cmake python-dev python-numpy python-tk libtbb-dev libeigen3-dev yasm libfaac-dev libopencore-amrnb-dev libopencore-amrwb-dev libtheora-dev libvorbis-dev libxvidcore-dev libx264-dev libqt4-dev libqt4-opengl-dev sphinx-common texlive-latex-extra libv4l-dev libdc1394-22-dev libavcodec-dev libavformat-dev libswscale-dev default-jdk ant libvtk5-qt4-dev unzip cmake git python-dev python-numpy libboost-dev libboost-python-dev libboost-system-dev
# 必要な pip パッケージのインストール
sudo pip install numpy scipy matplotlib cython scikit-image dlib pandas txaio
# OpenCVのインストール
wget http://downloads.sourceforge.net/project/opencvlibrary/opencv-unix/3.0.0/opencv-3.0.0.zip
unzip opencv-3.0.0.zip
cd opencv-3.0.0
cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local -D WITH_TBB=ON -D BUILD_NEW_PYTHON_SUPPORT=ON -D WITH_V4L=ON -D WITH_FFMPEG=OFF -D BUILD_opencv_python2=ON .
make -j`nproc`
sudo make install
sudo cp ~/opencv-3.0.0/lib/cv2.so /usr/local/lib/python2.7/site-packages/
sudo ln /dev/null /dev/raw1394
# Torchのインストール
git clone https://github.com/torch/distro.git ~/torch --recursive
cd ~/torch
sudo dpkg --configure -a
bash install-deps
./install.sh # 最後にTorchをパスに追加するかどうか聞かれるので、yes
source ~/.bashrc
which th
# which th でpathが出力されない場合は下記を実行
# export PATH=~/torch/bin:$PATH;
# export LD_LIBRARY_PATH=~/torch/lib:$LD_LIBRARY_PATH;
# Torch用のLUAパッケージをインストール
for NAME in dpnn nn optim optnet csvigo cutorch cunn fblualib torchx tds image nngraph; do luarocks install $NAME; done
# OpenFaceのインストール
git clone https://github.com/cmusatyalab/openface ~/openface --recursive
cd ~/openface
sudo python setup.py install
# 追加で必要なものをインストール
cd ~/openface
./models/get-models.sh
./demos/web/install-deps.sh
sudo pip install -r demos/web/requirements.txt
---- ここまで ----
3. 動かしてみよう
手順2までで仮想マシンのセットアップ、必要なソフトウェアのインストールが完了しました。もうサンプルアプリが動く状態になっているはずです。
サンプルアプリを動かすには、ホストPCのブラウザから仮想マシンへアクセスする必要があります。そのために、仮想マシンのIPアドレスを調べましょう。端末アプリで「ifconfig」コマンドを実行してください。

IPアドレスを調べたら、「~/openface/demos/web/start-servers.sh」を実行しましょう。リアルタイムな顔学習・認識のデモプログラムが起動し、ブラウザからアクセスできるようになります。
下図のように「Starting factory ~~」というログが表示されたら正常に動作しています。
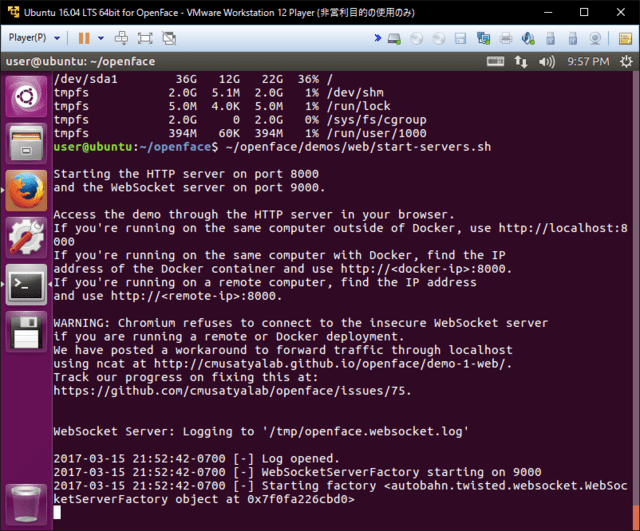
デモプログラムが起動したら、ホストOSのブラウザから先ほどのIPアドレスを使って下記URLへアクセスしてみてください。
http://<IPアドレス>:8000
どうでしょう?下図のような画面が見えましたか?この画面が見えていれば、しっかりと動いています! (※)
アクセスできると、Webカメラへの接続要求がポップアップで表示されます。許可してあげると、顔認識を開始しますので、お試しあれ。
※Webカメラの接続要求を許可するまでは、下図のようなカメラ映像は表示されません。

さて、ここまで読んでいただきありがとうございます。
一応、コマンド等は動くことを確認してこちらに記載していますが、環境によっては動かないかもしれませんので、あしからず。
今回はリアルタイムな顔認識のデモプログラムを実行しましたが、他にも顔がどのくらい似ているかの比較や、顔画像の人物分類のデモプログラムもあります。ご興味がありましたら、ぜひ触ってみてください。具体的な使い方は公式HPに記載されています。
今年度はこれで最後の投稿となります。
読んでいただいた皆様、どうもありがとうございました!
参考リンク
・OpenFace公式HP
https://cmusatyalab.github.io/openface/
・GitHub
https://github.com/cmusatyalab/openface
・OpenCVとdlibとOpenFaceでの顔検出と知見まとめ
http://vaaaaaanquish.hatenablog.com/entry/2016/06/28/004811
--------------
monipet
動物病院の犬猫の見守りをサポート
病院を離れる夜間でも安心
ASSE/CORPA
センサー、IoT、ビッグデータを活用して新たな価値を創造
「できたらいいな」を「できる」に
OSGi対応 ECHONET Lite ミドルウェア
短納期HEMS開発をサポート!
GuruPlug
カードサイズ スマートサーバ
株式会社ジェイエスピー
横浜に拠点を置くソフトウェア開発・システム開発・
製品開発(monipet)、それに農業も手がけるIT企業
今回は実際にOpenFaceをインストールして、リアルタイムな顔認識デモを動かすまでの流れを解説したいと思います。ある程度Linuxの知識がある人を対象に書いています。
※試す際には、WebカメラとPCをご用意ください。
下記の流れで解説します。
1. Ubuntu仮想マシンの作成
2. OpenFaceおよび必要なソフトウェアのインストール
3. 動かしてみよう
※手順1と2はDockerを使うことでスキップできるようです。詳しくはこちら。
Dockerだと中身に触りづらいため、今回は自力でセットアップします。
具体的な解説に入る前に・・・今回使用したPCはこんな構成です。
・OS … Windows 7 Professional 64bit
・CPU … Core i5 3230M (2コア4スレッド)
・メインメモリ … 12GB
・ストレージ … SSD
※2013年代に発売したノートPCです。
--------
1. Ubuntu仮想マシンの作成
まずは動作環境を構築します。今回はVMWare Workstation Playerの仮想マシンにUbuntuをインストールして使用します。(VMWare Workstation Playerは個人利用の場合のみ無料で使える仮想マシン環境です。この記事ではすでにインストールされているものとします。)
ここから「Ubuntu 16.04 LTS 64bit版」のOSイメージファイルを取得してください。(2017年3月現在では「ubuntu-ja-16.04-desktop-amd64.iso」というファイルがダウンロードできました。)
ダウンロードしたら、そのOSイメージファイルを使ってVMWare Workstation Playerで新規VMをセットアップしてください。パワーオン後、自動的にOSがインストールされます。
セットアップ時のハードウェア構成では下図のようにハードディスク容量を40GB以上に設定してください。(初期容量でも足りますが、念のためです。)
ユーザ名やパスワード等を設定しつつOSのインストールが完了すると、自動的に再起動してログイン画面が表示されます。そのままログインして、ソフトウェアアップデートをしましょう。弊社ではアップデート完了まで20~30分ほど時間がかかりました。
アップデートが終わったら、再起動してください。
2. OpenFaceおよび必要なソフトウェアのインストール
次に、OpenFace本体とOpenFaceの動作に必要なソフトウェアをインストールします。端末アプリを起動してください。
端末アプリが起動したら、下記のコマンドを順に実行してください。長いですが、すべて必要なソフトウェアです。こちらも時間がかかります。弊社では全て実行し終わるまで1時間30分ほどかかりました。
※入力が必要なコマンドが混ざっていますので、一括実行は避けてください。
---- ここから ----
# aptパッケージの更新
sudo apt update
sudo apt upgrade
# 必要な apt パッケージのインストール
sudo apt install python-setuptools python-pip liblapack-dev libatlas-base-dev gfortran g++ build-essential libgtk2.0-dev libjpeg-dev libtiff5-dev libjasper-dev libopenexr-dev cmake python-dev python-numpy python-tk libtbb-dev libeigen3-dev yasm libfaac-dev libopencore-amrnb-dev libopencore-amrwb-dev libtheora-dev libvorbis-dev libxvidcore-dev libx264-dev libqt4-dev libqt4-opengl-dev sphinx-common texlive-latex-extra libv4l-dev libdc1394-22-dev libavcodec-dev libavformat-dev libswscale-dev default-jdk ant libvtk5-qt4-dev unzip cmake git python-dev python-numpy libboost-dev libboost-python-dev libboost-system-dev
# 必要な pip パッケージのインストール
sudo pip install numpy scipy matplotlib cython scikit-image dlib pandas txaio
# OpenCVのインストール
wget http://downloads.sourceforge.net/project/opencvlibrary/opencv-unix/3.0.0/opencv-3.0.0.zip
unzip opencv-3.0.0.zip
cd opencv-3.0.0
cmake -D CMAKE_BUILD_TYPE=RELEASE -D CMAKE_INSTALL_PREFIX=/usr/local -D WITH_TBB=ON -D BUILD_NEW_PYTHON_SUPPORT=ON -D WITH_V4L=ON -D WITH_FFMPEG=OFF -D BUILD_opencv_python2=ON .
make -j`nproc`
sudo make install
sudo cp ~/opencv-3.0.0/lib/cv2.so /usr/local/lib/python2.7/site-packages/
sudo ln /dev/null /dev/raw1394
# Torchのインストール
git clone https://github.com/torch/distro.git ~/torch --recursive
cd ~/torch
sudo dpkg --configure -a
bash install-deps
./install.sh # 最後にTorchをパスに追加するかどうか聞かれるので、yes
source ~/.bashrc
which th
# which th でpathが出力されない場合は下記を実行
# export PATH=~/torch/bin:$PATH;
# export LD_LIBRARY_PATH=~/torch/lib:$LD_LIBRARY_PATH;
# Torch用のLUAパッケージをインストール
for NAME in dpnn nn optim optnet csvigo cutorch cunn fblualib torchx tds image nngraph; do luarocks install $NAME; done
# OpenFaceのインストール
git clone https://github.com/cmusatyalab/openface ~/openface --recursive
cd ~/openface
sudo python setup.py install
# 追加で必要なものをインストール
cd ~/openface
./models/get-models.sh
./demos/web/install-deps.sh
sudo pip install -r demos/web/requirements.txt
---- ここまで ----
3. 動かしてみよう
手順2までで仮想マシンのセットアップ、必要なソフトウェアのインストールが完了しました。もうサンプルアプリが動く状態になっているはずです。
サンプルアプリを動かすには、ホストPCのブラウザから仮想マシンへアクセスする必要があります。そのために、仮想マシンのIPアドレスを調べましょう。端末アプリで「ifconfig」コマンドを実行してください。
IPアドレスを調べたら、「~/openface/demos/web/start-servers.sh」を実行しましょう。リアルタイムな顔学習・認識のデモプログラムが起動し、ブラウザからアクセスできるようになります。
下図のように「Starting factory ~~」というログが表示されたら正常に動作しています。
デモプログラムが起動したら、ホストOSのブラウザから先ほどのIPアドレスを使って下記URLへアクセスしてみてください。
http://<IPアドレス>:8000
どうでしょう?下図のような画面が見えましたか?この画面が見えていれば、しっかりと動いています! (※)
アクセスできると、Webカメラへの接続要求がポップアップで表示されます。許可してあげると、顔認識を開始しますので、お試しあれ。
※Webカメラの接続要求を許可するまでは、下図のようなカメラ映像は表示されません。
さて、ここまで読んでいただきありがとうございます。
一応、コマンド等は動くことを確認してこちらに記載していますが、環境によっては動かないかもしれませんので、あしからず。
今回はリアルタイムな顔認識のデモプログラムを実行しましたが、他にも顔がどのくらい似ているかの比較や、顔画像の人物分類のデモプログラムもあります。ご興味がありましたら、ぜひ触ってみてください。具体的な使い方は公式HPに記載されています。
今年度はこれで最後の投稿となります。
読んでいただいた皆様、どうもありがとうございました!
参考リンク
・OpenFace公式HP
https://cmusatyalab.github.io/openface/
・GitHub
https://github.com/cmusatyalab/openface
・OpenCVとdlibとOpenFaceでの顔検出と知見まとめ
http://vaaaaaanquish.hatenablog.com/entry/2016/06/28/004811
--------------
monipet
動物病院の犬猫の見守りをサポート
病院を離れる夜間でも安心
ASSE/CORPA
センサー、IoT、ビッグデータを活用して新たな価値を創造
「できたらいいな」を「できる」に
OSGi対応 ECHONET Lite ミドルウェア
短納期HEMS開発をサポート!
GuruPlug
カードサイズ スマートサーバ
株式会社ジェイエスピー
横浜に拠点を置くソフトウェア開発・システム開発・
製品開発(monipet)、それに農業も手がけるIT企業