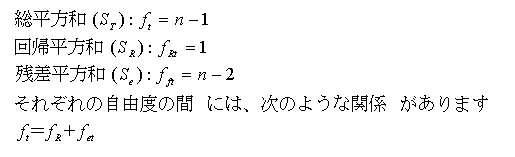第2単元では、いよいよ統計モデルを学びます。ところで、統計モデルを毛嫌いする人って、世の中には、結構いるようです。しかし、思うに、道具は使いようです。とりあえず、知っていて損はないと思うので、頑張って学習してみます。
さて、最初に学ぶのは、回帰分析です。回帰分析とは、散布図で表される(ような)データに対して、尤もらしい(一次)方程式を、数学的に当てはめることです。(一次)方程式を、散布図に当てはめることによって、散布図にあるデータをもちいて、データの出現を予測することが可能になります。
まず、直観的に回帰分析を理解してみましょう。
下の散布図は、身長と体重の関係をプロットしたものです。散布図を見ると、身長が高くなるほど、体重が増える傾向にあるといえそうです。もちろん、この傾向に矛盾したデータがあることは否定できません。がしかし、全体的な傾向としては、身長と体重は、比例関係にあるといっても良さそうです。いや、良いとしましょう。この辺のわり切りは、とても大事です。

散布図を眺めていると、なぜか、次のような疑問が浮かびました
「身長150cmの人は、どのくらいの体重になることが多いのか」
身長が150cmの時、体重は、大体、40~45kgになりそうです。でも、散布図を眺めるだけでは、正確なところは、よく分かりません。身長150cmの人の体重の平均値を計算することは、とても簡単です。でも、その場合、色々な人がいるのに、平均値で身長150cmの体重を代表させるのは、ちょっと強引な感じもします。そこで、身長150cmの人の体重を、その平均値と変動範囲を組み合わせた形で知ることを考えてみます。この場合、単純な平均値よりは、説得力がありそうです。では、どうすべきなのでしょうか。そこで、以下のような関係式を考えてみます。

つまり、「身長が150cmである各個人の体重は、その平均に誤差を加えた関係と考えられる」と仮定します。この式で重要なのは、式に「誤差」が含まれているところです。もし、誤差が含まれていなかったら、身長150cmの人の平均体重を主張するだけです。これだと物足りないのは、先に書いたとおりです。そこで、誤差を、式の中に含むことにしました。この結果、身長150cmである各個人の体重を、その平均値と変動範囲を用いて示すことが可能になります。でも、式(0.1)だけでは、少し使い勝手が悪い感じがします。なぜなら、身長が固定されているからです。あと、体重の平均も計算しなければなりません。どんな身長の時も、体重の平均をいちいち計算せずに、身長と体重の関係をあらわすには、どうすべきなのでしょうか。そこで、下の式のように考えてみることにします

なんだか、訳の分からないアルファベットとギリシャ文字が出てきましたね。でも、落ち着いて、上の式を良く観察します。まず、右辺に出てくるαとβは、未知数です。未知数の計算方法は、この先で学びます。ここでαとβとかいたのは、何か書いておかないと、後で訳がわからなくなるので、勝手なギリシャ文字で表してあるだけです。
左辺は、身長がx cmの各個人の体重です。一方、右辺は、左辺で決めた身長x cmと未知数βとの積に、これまた未知数αと誤差を足しています。さて、式(0.1)と式(0.2)を良く見比べてみましょう。式(0.1)から式(0.2)へは2つの点が変化しています。1つ目は、身長をxであらしたことです。身長をxであらわしたことで、特定の身長だけではなく、全ての身長を考えることが出来るようになりました。さて、問題は2番目です。

は

と変化しました。いま、全ての身長はxで表すことにしました。ということは、式(0.3)にある身長xの体重の平均を、式(0.4)では、身長xと未知数βとの積に、未知数αを加えて、改めて表現しなおしています。つまり、式(0.4)では、適当な未知数βとαを使うことで、身長から、その身長における体重の平均値を計算しようとしているのです。ここで、式(0.2)に、戻りましょう。すると、式(0.1)jから式(0.2)の変化とは、全ての身長xにおいて、適当な未知数βとαを用いて、各個人の体重を計算しようとしていることを意味します。
ここで話を転換して、同じ話を、こんどは未知数βとαから考えて見ましょう。いま、もし、未知数βとαを、何がしかの方法で、上手に計算してやることができたとします。すると、式(0.2)を用いて、身長からその身長における体重の平均値を経由して、各個人の体重を、誤差を明示しながら計算できることになります。結局、式(0.2)を用いれば、身長150cmのときの体重の平均値と誤差範囲を、数式に基づいて知ることが出来るのです。
そして、未知数β、αが決まった、この計算式こそが、図1の回帰直線です。すなわち、回帰直線とは、散布図上にある個々のデータの傾向を、誤差をも考慮しながら、たった一本の直線によって要約することと言えるのです。このような回帰直線を引くことを目的とした分析手法を、回帰分析といいます。