正規化は、あくまで個別のファイル/画面/レイアウトに基づく作業であり、全体としての正規化ではありません。(ファイル←→画面←→帳票での重複は排除されていません。)

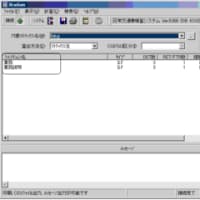
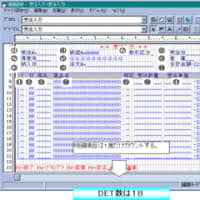
(図1)全体での正規化
そこで、エンティティのキー構造に着目して、エンティティの統合を行っていきます。
①.エンティティの統合
◆キー構造の同じエンティティの統合を検討していきます。
まずは、統合を検討する対象となるエンティティを特定します。各エンティティのキー構造に着目して、同じデータ項目の組合せをキーとして持っているエンティティを統合検討対象とします。
このとき、キーを構成するデータ項目の並び順は関係ありません。
例えば、Aというエンティティのキー構造が「商品コード」+「年月日」で、Bというエンティティが「年月日」+「商品コード」であっても、同じデータ項目でキーが構成されているため、このAとBのエンティティを統合するかどうが検討対象となります。
この例では、キーを構成するデータ項目数が2つでしたが、これが3つ、4つ・・・nと増えていくと、どのような項目で構成されており、その構成と同じ構成のエンティティを探すという作業も大変な作業となります。
弊社で取り扱っているXupper(クロスアッパー)では、機械的に同じキー構造のエンティティを検出するという機能を持っていますが、大規模なシステム開発においては、なんらかのツールを利用しなければ、このような単純な検討さえ困難な作業となります。
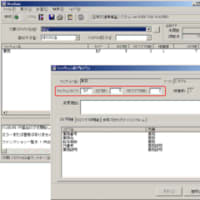
◆エンティティのキー構造がたとえ同じであったとしても、統合しない場合もあります。
エンティティのキー構造が同じ場合でも、管理対象データが異なる場合は、エンティティの統合は行いません。 管理対象が同じであれば、そのエンティティのキー構造は同じ構造になるはずです。
しかし、キー構造が同じだからといって、管理対象データが同一であるとは必ずしもいえないということに注意する必要があります。

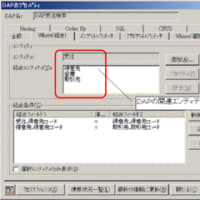
(図2)キー構造が同じで別エンティティの例
②.属性の統合
◆エンティティを統合した結果、第3正規形(One Fact in one place)になっているかどうか確認します。
まずは、異音同義語が存在しないかをチェックします。個別のテーブルや画面・帳票で同じデータ項目なのに別々のデータ項目名を付与していることはよくありますので注意が必要です。
◆次に、導出項目かどうかを検討していきます。
もともとの個別のデータモデルでは導出できなかったが、エンティティを統合した結果、実は導出可能な項目であったということもありますので、エンティティ統合後に確認しておく必要があります。
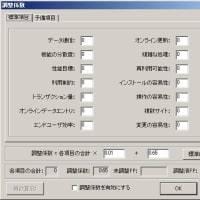
◆さらに、属性項目間の従属関係を確認していきます。
個別のデータモデルでは、該当するエンティティが存在しなかったが、モデルを統合した結果、ある属性は別のエンティティの属性であったということも良くありますので、データ項目間の依存関係(関数従属性)についても、再度確認するようにします。

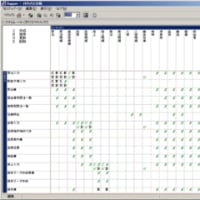
(図3)データ項目間の依存関係の再確認
③.リレーションの統合(見直し)
◆統合した結果、元のエンティティに定義されていたリレーションが冗長になっていないか確認します。

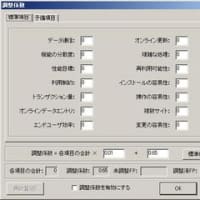
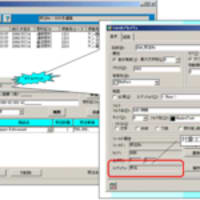
(図4)冗長なリレーションの確認
画面Aを正規化して作成したモデルと画面Bを正規化して作成したモデルにそれぞれ、エンティティCとエンティティC’が存在しかつ、キー構造が同じためエンティティを統合して、統合モデルを作成したとします。この場合、エンティティCとエンティティC’を統合した結果、エンティティC→エンティティB→エンティティAと特定することが可能であるにもかかわらず、エンティティCとエンティティAとの間にリレーションが残ってしまいます。
このような冗長なリレーション(エンティティAとエンティティC間のリレーション)は排除(削除)します。
(図1)全体での正規化
そこで、エンティティのキー構造に着目して、エンティティの統合を行っていきます。
①.エンティティの統合
◆キー構造の同じエンティティの統合を検討していきます。
まずは、統合を検討する対象となるエンティティを特定します。各エンティティのキー構造に着目して、同じデータ項目の組合せをキーとして持っているエンティティを統合検討対象とします。
このとき、キーを構成するデータ項目の並び順は関係ありません。
例えば、Aというエンティティのキー構造が「商品コード」+「年月日」で、Bというエンティティが「年月日」+「商品コード」であっても、同じデータ項目でキーが構成されているため、このAとBのエンティティを統合するかどうが検討対象となります。
この例では、キーを構成するデータ項目数が2つでしたが、これが3つ、4つ・・・nと増えていくと、どのような項目で構成されており、その構成と同じ構成のエンティティを探すという作業も大変な作業となります。
弊社で取り扱っているXupper(クロスアッパー)では、機械的に同じキー構造のエンティティを検出するという機能を持っていますが、大規模なシステム開発においては、なんらかのツールを利用しなければ、このような単純な検討さえ困難な作業となります。
◆エンティティのキー構造がたとえ同じであったとしても、統合しない場合もあります。
エンティティのキー構造が同じ場合でも、管理対象データが異なる場合は、エンティティの統合は行いません。 管理対象が同じであれば、そのエンティティのキー構造は同じ構造になるはずです。
しかし、キー構造が同じだからといって、管理対象データが同一であるとは必ずしもいえないということに注意する必要があります。
(図2)キー構造が同じで別エンティティの例
②.属性の統合
◆エンティティを統合した結果、第3正規形(One Fact in one place)になっているかどうか確認します。
まずは、異音同義語が存在しないかをチェックします。個別のテーブルや画面・帳票で同じデータ項目なのに別々のデータ項目名を付与していることはよくありますので注意が必要です。
◆次に、導出項目かどうかを検討していきます。
もともとの個別のデータモデルでは導出できなかったが、エンティティを統合した結果、実は導出可能な項目であったということもありますので、エンティティ統合後に確認しておく必要があります。
◆さらに、属性項目間の従属関係を確認していきます。
個別のデータモデルでは、該当するエンティティが存在しなかったが、モデルを統合した結果、ある属性は別のエンティティの属性であったということも良くありますので、データ項目間の依存関係(関数従属性)についても、再度確認するようにします。
(図3)データ項目間の依存関係の再確認
③.リレーションの統合(見直し)
◆統合した結果、元のエンティティに定義されていたリレーションが冗長になっていないか確認します。
(図4)冗長なリレーションの確認
画面Aを正規化して作成したモデルと画面Bを正規化して作成したモデルにそれぞれ、エンティティCとエンティティC’が存在しかつ、キー構造が同じためエンティティを統合して、統合モデルを作成したとします。この場合、エンティティCとエンティティC’を統合した結果、エンティティC→エンティティB→エンティティAと特定することが可能であるにもかかわらず、エンティティCとエンティティAとの間にリレーションが残ってしまいます。
このような冗長なリレーション(エンティティAとエンティティC間のリレーション)は排除(削除)します。