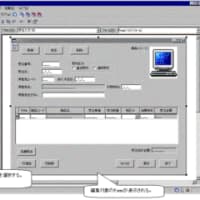
データ項目を捕捉した後に行う作業として、データ項目間の依存関係の分析というものがあります。依存関係を関数従属性と呼んだりもします。
なんとなく、難しそうな言葉ですが、「Aというデータ項目の値がきまったら、Bというデータ項目の値も決まる」ということを「BはAに従属する」とか「BはAに関数従属する」と表現します。
y=f(x)で、xが決まればyが決まるというのと一緒です。
このようなデータ項目間の関係を整理していく必要があるわけですが・・・
では、どうやって整理すればいいのでしょうか?
①システム仕様書を分析する
もっとも簡単でよく行う方法は、現行システムのファイル・テーブルレイアウトを分析するという方法です。
具体的には「テーブル仕様書」「ファイル設計書」「インタフェース仕様書」といったドキュメントに記述されているデータ項目間の関係を整理していくということです。
基本的にこれらのドキュメントを参照すれば、ファイルやテーブルのキーがわかるはずですので、キーとそれ以外のデータ項目間に依存関係があるということはすぐにわかります。
例えば、”得意先”ファイルのキーが「得意先コード」だった場合、この項目が決まれば、得意先データが特定できるというのは、すぐにわかります。

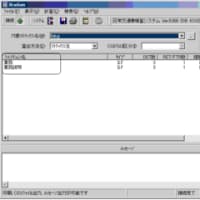
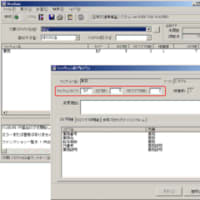
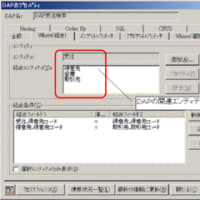
(図1)テーブル定義書からの分析
しかし、キー以外の属性項目間の依存関係についても、分析をしておく必要があります。
上記の”得意先”ファイルの属性として、「得意先担当者コード」と「得意先担当者名」というデータ項目があった場合、「得意先担当者コード」が決まれば「得意先担当者名」が決まるという関係ですから、「得意先担当者コード」と「得意先担当者名」との間にも関数従属性があるということになります。
②リバース・エンジニアリング
分析を行うためのドキュメントが存在していないという場合は、実際のデータベースからリバースエンジニアリングを検討します。
市販のRDBMSのほとんどは、ツール(ERwin、ER/Studio、Xupper、DataIntimate等)を使用することにより物理DBからデータモデルへリバースすることが可能です。
基本的に、物理DBであればキーが設定されているはずですので、キーが何かはすぐに整理できるはずです。
また、キー以外の属性項目間の依存関係の把握も目的とします。
一旦、データモデルへリバースしておくと、データ項目間の従属関係の分析のみではなく、それ以降の作業についても利用することができます。
ただし、物理DBをリバースする場合に気をつけることがあります。それは、物理DBの定義の際には通常英数字でカラム名をつけるということです。その場合には項目名を見ただけでは何を意味しているのか理解できないことがあります。
③画面レイアウトを分析する
画面レイアウトを分析することにより、データ項目間の関数従属性を検討していきます。
画面レイアウトであれば、入力項目と出力項目の関係をもとに依存関係を分析することが可能です。
例えば、”得意先コード”を入力することにより”得意先名”を画面表示するという関係があれば、”得意先名”は”得意先コード”に従属しているという判断ができるわけです。
あえて画面レイアウトのみを対象とし、帳票レイアウトを対象としていない理由は、帳票レイアウトではデータ項目名のみを手がかりに従属性を検討する必要があり、作業として非常に大変な作業となるからです。
⑤データの用語構成に着目する
画面レイアウトの情報もテーブルレイアウトの情報も入手できないという場合は、どうやってデータ項目間の関係を整理していけばよいのでしょうか。
その場合は、データ項目名を「修飾語」「主要語」「区分語」に分解して主要語に着目してグループ化することから始めます。

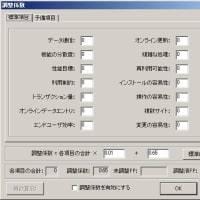
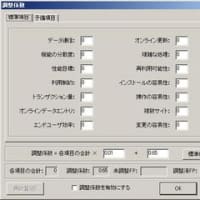
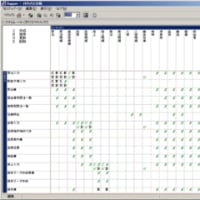
(図2)区分語での分析
まず、「区分語」に着目して、どの項目がキーになりそうなのか検討していきます。よほど、いい加減な命名をしていないかぎり、データ項目名にもある程度法則性があるはずです。
例えば、キーとなるようなデータ項目については、通常「○○コード」「○○番号」「○○ID」「○○区分」という命名がされているはずです。
そのような項目を抽出し、「○○」というところを「主要語」としてその「主要語」を含む全てのデータ項目を一つのグループに機械的にまとめるだけで、ある程度の整理を行うことができます。
一旦、グループ化をしたら、あとの作業は他の方法と同様です。
⑥インタビューを行う
開発者だけで検討をしても限界があります。承認を得るという意味においても、ユーザさんにインタビューをする必要があります。 「○○コード」と「○○名」という関係であれば、割と理解しやすいのですが、複合キーの(複数のデータ項目でキーが構成される)場合は、どのデータ項目とどのデータ項目の値がきまったら、他のデータ項目が決まるのか、ユーザさんにインタビューしてみないとわからないということがあります。
しかし、ユーザさんに「このデータのキーは何ですか?」と質問してもあまり答えてくれないのではないでしょうか。その場合、まず、キーとは何かからの説明をしていく必要が出てきます。
そのような聞き方をするのではなく、「このデータ(情報)はどのいう単位で管理していますか?」という言い回しをすることが重要です。(基本的にシステムの用語はできるだけ使わないように心がけることが重要です。)
なんとなく、難しそうな言葉ですが、「Aというデータ項目の値がきまったら、Bというデータ項目の値も決まる」ということを「BはAに従属する」とか「BはAに関数従属する」と表現します。
y=f(x)で、xが決まればyが決まるというのと一緒です。
このようなデータ項目間の関係を整理していく必要があるわけですが・・・
では、どうやって整理すればいいのでしょうか?
①システム仕様書を分析する
もっとも簡単でよく行う方法は、現行システムのファイル・テーブルレイアウトを分析するという方法です。
具体的には「テーブル仕様書」「ファイル設計書」「インタフェース仕様書」といったドキュメントに記述されているデータ項目間の関係を整理していくということです。
基本的にこれらのドキュメントを参照すれば、ファイルやテーブルのキーがわかるはずですので、キーとそれ以外のデータ項目間に依存関係があるということはすぐにわかります。
例えば、”得意先”ファイルのキーが「得意先コード」だった場合、この項目が決まれば、得意先データが特定できるというのは、すぐにわかります。
(図1)テーブル定義書からの分析
しかし、キー以外の属性項目間の依存関係についても、分析をしておく必要があります。
上記の”得意先”ファイルの属性として、「得意先担当者コード」と「得意先担当者名」というデータ項目があった場合、「得意先担当者コード」が決まれば「得意先担当者名」が決まるという関係ですから、「得意先担当者コード」と「得意先担当者名」との間にも関数従属性があるということになります。
②リバース・エンジニアリング
分析を行うためのドキュメントが存在していないという場合は、実際のデータベースからリバースエンジニアリングを検討します。
市販のRDBMSのほとんどは、ツール(ERwin、ER/Studio、Xupper、DataIntimate等)を使用することにより物理DBからデータモデルへリバースすることが可能です。
基本的に、物理DBであればキーが設定されているはずですので、キーが何かはすぐに整理できるはずです。
また、キー以外の属性項目間の依存関係の把握も目的とします。
一旦、データモデルへリバースしておくと、データ項目間の従属関係の分析のみではなく、それ以降の作業についても利用することができます。
ただし、物理DBをリバースする場合に気をつけることがあります。それは、物理DBの定義の際には通常英数字でカラム名をつけるということです。その場合には項目名を見ただけでは何を意味しているのか理解できないことがあります。
③画面レイアウトを分析する
画面レイアウトを分析することにより、データ項目間の関数従属性を検討していきます。
画面レイアウトであれば、入力項目と出力項目の関係をもとに依存関係を分析することが可能です。
例えば、”得意先コード”を入力することにより”得意先名”を画面表示するという関係があれば、”得意先名”は”得意先コード”に従属しているという判断ができるわけです。
あえて画面レイアウトのみを対象とし、帳票レイアウトを対象としていない理由は、帳票レイアウトではデータ項目名のみを手がかりに従属性を検討する必要があり、作業として非常に大変な作業となるからです。
⑤データの用語構成に着目する
画面レイアウトの情報もテーブルレイアウトの情報も入手できないという場合は、どうやってデータ項目間の関係を整理していけばよいのでしょうか。
その場合は、データ項目名を「修飾語」「主要語」「区分語」に分解して主要語に着目してグループ化することから始めます。
(図2)区分語での分析
まず、「区分語」に着目して、どの項目がキーになりそうなのか検討していきます。よほど、いい加減な命名をしていないかぎり、データ項目名にもある程度法則性があるはずです。
例えば、キーとなるようなデータ項目については、通常「○○コード」「○○番号」「○○ID」「○○区分」という命名がされているはずです。
そのような項目を抽出し、「○○」というところを「主要語」としてその「主要語」を含む全てのデータ項目を一つのグループに機械的にまとめるだけで、ある程度の整理を行うことができます。
一旦、グループ化をしたら、あとの作業は他の方法と同様です。
⑥インタビューを行う
開発者だけで検討をしても限界があります。承認を得るという意味においても、ユーザさんにインタビューをする必要があります。 「○○コード」と「○○名」という関係であれば、割と理解しやすいのですが、複合キーの(複数のデータ項目でキーが構成される)場合は、どのデータ項目とどのデータ項目の値がきまったら、他のデータ項目が決まるのか、ユーザさんにインタビューしてみないとわからないということがあります。
しかし、ユーザさんに「このデータのキーは何ですか?」と質問してもあまり答えてくれないのではないでしょうか。その場合、まず、キーとは何かからの説明をしていく必要が出てきます。
そのような聞き方をするのではなく、「このデータ(情報)はどのいう単位で管理していますか?」という言い回しをすることが重要です。(基本的にシステムの用語はできるだけ使わないように心がけることが重要です。)