Google Apps Scripts はサーバーサイドのJavaScript、と呼ばれています。その魅力を象徴するUrlFetchApp.fetchというものを使ってみました。
RSSやURLを使ってその情報を活用してスプレッドシートなどのGoogleのサービスと連動させる事ができます。今回はスプレッドシートを中心にやってみましょう。
RSSを読むには専用のアプリやサービスを使用しますが、実はいきなりスプレッドシートからアクセスする事ができます。
UrlFetchApp.fetch→Xml.parse
と加工して行くと、RSSの中身を参照できる様になります。
RSSはサイトごとに違います。そのXMLの構造を把握した上で、getElement()でツリーを下って行く感じでしょうか。
例えばむねさださんのRSSをのぞいてみましょう。のぞくのはパソコンのchromeが便利です。ソースからRSSのアドレスをコピペしてアドレスの窓に入れると見れます。

XMLはよくわからないのですが、タグ(?)に注目します。
どうやら、<channel>というタグの下に<item>というタグがあり、その下に各記事が書いてある様です。<item>の下には<title>や<link>などがあります。<content:encoded>タグが本文の様ですね。
残念な事にXml.parseではこの「コロンが挟まっているタグ」を取得することができない模様です。
(ですので、むねさださんのブログRSSから本文をスプレッドシートへ、とは単純には行けない模様です。また、そもそも本文が無いRSSもありますね。)
これらのRSSにあるタグの名前を指定してプロパティ(?)をのぞいて行く、いう様な感じになります。
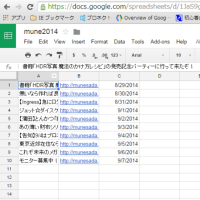
試しに、タイトルとURLと更新日時をぶっこぬくとすると、こんな感じ。
タイトル→title
URL→link
更新日時→pubDate
というタグですね。
RSSやURLを使ってその情報を活用してスプレッドシートなどのGoogleのサービスと連動させる事ができます。今回はスプレッドシートを中心にやってみましょう。
RSSの中身を読み取る
RSSを読むには専用のアプリやサービスを使用しますが、実はいきなりスプレッドシートからアクセスする事ができます。
UrlFetchApp.fetch→Xml.parse
と加工して行くと、RSSの中身を参照できる様になります。
RSSはサイトごとに違います。そのXMLの構造を把握した上で、getElement()でツリーを下って行く感じでしょうか。
例えばむねさださんのRSSをのぞいてみましょう。のぞくのはパソコンのchromeが便利です。ソースからRSSのアドレスをコピペしてアドレスの窓に入れると見れます。
XMLはよくわからないのですが、タグ(?)に注目します。
どうやら、<channel>というタグの下に<item>というタグがあり、その下に各記事が書いてある様です。<item>の下には<title>や<link>などがあります。<content:encoded>タグが本文の様ですね。
残念な事にXml.parseではこの「コロンが挟まっているタグ」を取得することができない模様です。
(ですので、むねさださんのブログRSSから本文をスプレッドシートへ、とは単純には行けない模様です。また、そもそも本文が無いRSSもありますね。)
これらのRSSにあるタグの名前を指定してプロパティ(?)をのぞいて行く、いう様な感じになります。
試しに、タイトルとURLと更新日時をぶっこぬくとすると、こんな感じ。
タイトル→title
URL→link
更新日時→pubDate
というタグですね。
function munesada(){
var bookurl = URL_BOOK;
var sheetName = SHEET_NAME;
var book = SpreadsheetApp.openByUrl(bookurl);
var sheet2 = book.getSheetByName(sheetName);
var rss = 'http://munesada.com/feed';
var response = UrlFetchApp.fetch(rss);
var lastRow = sheet2.getLastRow()+1;
var lastColumn = sheet2.getLastColumn()+1;
//Logger.log(lastpubDay);
var feed = response.getContentText();
//Logger.log(feed);
var xml = Xml.parse(response.getContentText(), false);
var items = xml.getElement().getElement('channel').getElements('item');
//Logger.log(items);
var jsonArray = [];
for(var i = 0; i < items.length; i++) {
var json = {};
// 記事のタイトル
var title = items[i].getElement('title').getText();
// 記事URL
var url = items[i].getElement('link').getText();
//更新日時
var date = items[i].getElement('pubDate').getText();
var pubDate = new Date(date);
json = {'title' : title , 'url' : url , 'pubDate' : pubDate }
//Logger.log(JSON.stringify(json));
jsonArray.push(json);
//Logger.log(JSON.stringify(jsonArray));
};
jsonArray.sort(
function (a,b){
var aDate = a['pubDate'];
var bDate = b['pubDate'];
return aDate - bDate ;
}
);
for ( j = 0 ; j < jsonArray.length ; j++){
var range = sheet2.getRange(lastRow+j,1,lastRow+j,3)
range.getCell(1, 1).setValue(jsonArray[j]['title']);
range.getCell(1, 2).setValue(jsonArray[j]['url']);
range.getCell(1, 3).setValue(jsonArray[j]['pubDate']);
};
//Browser.msgBox('URLを出力しました。');
};</pre>
色々チマチマ変数に入れるのがコツと言うか主流の様です。
var response = UrlFetchApp.fetch(rss);
var xml = Xml.parse(response.getContentText(), false);
の2つでRSSの中身を読み取りまして、
var items = xml.getElement().getElement('channel').getElements('item');
で前述のRSSのタグを下って行ってます。
<channel>タグの下の<item>タグ、とgetElement()を参照して行きます。
まぁ、他サイト様からコピペして色々試したところこんな感じになりました。
 ▲はい、できました!
▲はい、できました!
実行時に警告がでるのでこの方法でのパースはやがて使えなくなるかもしれません。
恐らくこっちを使えば・・・名前空間・・・ハテ?_| ̄|○
Class XmlService - Google Apps Script ? Google Developers
URLからHTMLを取得する
本文は残念な事に取得ができない事が多く、今回のむねさださんの様な場合や、J'sgoal様のRSSの様にそもそも配信自体が無い場合もあります。ですのでHTMLを全てぶっこぬいて、そこからチマチマ文字列を加工して行きます。
DOMが使えず、文字列の加工である点がポイントでしょうか。
UrlFetchApp.fetchというのでブラウザに表示することなく、HTMLを取得し、テキストにした後、チマチマ目的の本文を探していきます。
ここでマネさせていただいたのがryo m.さんのgetStringSliceという関数です。
indexOfを利用して開始文字列と終了文字列の間だけを返してくれます。
HTMLとにらめっこしながら、都合のいい文字列(多くはタグ)を指定して中身をぶっこぬくわけですね。
function getStringSlice(content, startStr, endStr){
var indexStart = content.indexOf(startStr);
if(indexStart == -1){
return "";
} else {
indexStart += startStr.length
return content.slice(indexStart, content.indexOf(endStr, indexStart));
}
}▲ryo m.さんの関数「getStringSlice」indexOfがポイントの様ですが・・・( ´ ▽ ` )ノ←よくわかっていません。
 ぼどレポ: Google スプレッドシートを超簡易DBとして使う その1
ぼどレポ: Google スプレッドシートを超簡易DBとして使う その1
主に東京のボードゲーム会のレポートと実際に遊んだボードゲームのレビューを公開しています。 基本的に土日のどちらかは、どこぞのボドゲ会に参加しておりますので、見かけたらどうぞよろしく!...
まず、HTMLの取得ですがUrlFetchApp.fetch()というもので取得したのち、getContentText()というので文字列にします。
地味にハマったのが、J'sgoalの文字コードがShift_JISで文字化けが凄かった点。リファレンスの英語を頑張って読んでみたところ、どうやらgetContentTextで指定できる様でした。よかったです。
オプションはデフォでもいけましたが、念のため設定してあります。
data.getContentText("Shift_JIS")という感じで文字コードを指定する事ができました。
var opt = {"contentType":"text/html;","method":"get"};
var data = UrlFetchApp.fetch(url ,opt);
var content= data.getContentText("Shift_JIS");
例えば、むねさださんの記事の本文を取得してみましょう。
これぞ未来のメガネ!iPhoneと連携して光ったり音を鳴らす「雰囲気メガネ」がすごいぞ! | むねさだブログ
むねさださんのこの記事の本文はどうやら
<div class="entry-content">
</div><!-- .entry-content -->
というタグに記述してある模様です。こちらを前述のgetStringSlice関数にぶち込みます。
むねさださんの文字コードはUTF-8でしたので特に変更せずそのままいけました。
function munesadaHonbun(){
var bookurl = URL_BOOK;
var sheetName = SHEET_NAME;
var book = SpreadsheetApp.openByUrl(bookurl);
var sheet = book.getSheetByName(sheetName);
var lastRow = sheet.getLastRow()+1;
//var lastColumn = sheet.getLastColumn()+1;
var url = "http://munesada.com/2014/09/06/blog-3705";
//html取得
var opt = {"contentType":"text/html;","method":"get"};
var data = UrlFetchApp.fetch(url ,opt);
var content= data.getContentText();
Logger.log(content);
var postText = getStringSlice(content, '', '');
var range = sheet.getRange(lastRow,1,lastRow,4);
Logger.log(postText);
range.getCell(1, 4).setValue(postText);
}
function getStringSlice(content, startStr, endStr){
var indexStart = content.indexOf(startStr);
if(indexStart == -1){
return "";
} else {
indexStart += startStr.length
return content.slice(indexStart, content.indexOf(endStr, indexStart));
}
}
 ▲本文のHTMLを取得しました!!
▲本文のHTMLを取得しました!!
getStringSliceという関数の引数にHTMLの入った変数と最初の区切り文字列と最後の区切り文字列を渡しています。
残念ながらDOMの.innerText的なものは無いようですので、正規表現とかでチマチマ行く感じでしょうか?
私は、別のアプリでHTMLとして使う予定なのでこのままで良しとしました。
サーバーサイドJavaScript
JavaScriptは見ているサイトに対して色々と働きかける事ができます。
逆に言えば見てないサイトに対しては中々難しい場合もあります。サーバーで動くGoogle Apps Scripts ならばより柔軟に対応ができます。
興味のある方はぜひお試し下さい。楽しいですよ。
最後に、今回作成したコンサドーレ札幌のレポート記事データベースにアクセスするMyScripts用のスクリプトです。
扱うデータベースが変わっています。タイトルやURL、更新日時を追加しました。
スクリプト自体はあまり前回のとは変わっていませんけどね。( ´ ▽ ` )ノ
登録はこちら→http://tinyurl.com/kgu8lhq
 MyScripts 2.5
MyScripts 2.5
分類: 仕事効率化,ユーティリティ
価格: ¥400 (Takeyoshi Nakayama)