国立大学職員日記
メインコンテンツ
→
国立大学職員日記:記事一覧
CALENDAR
2011年7月
日
月
火
水
木
金
土
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
前月
翌月
ENTRY ARCHIVE
2014年08月
2014年04月
2014年03月
2013年04月
2013年03月
2013年02月
2013年01月
2012年12月
2012年11月
2012年10月
2012年09月
2012年08月
2012年07月
2012年06月
2012年05月
2012年04月
2012年03月
2012年02月
2012年01月
2011年12月
2011年11月
2011年10月
2011年09月
2011年08月
2011年07月
2011年06月
2011年05月
2011年04月
2011年03月
2011年02月
2011年01月
2010年12月
2010年11月
2010年10月
2010年09月
2010年08月
2010年07月
2010年06月
2010年05月
2010年04月
2010年03月
2010年02月
2010年01月
2009年12月
2009年11月
2009年10月
2009年09月
2009年07月
2009年06月
2009年05月
2009年04月
2009年03月
2009年02月
2009年01月
2008年12月
2008年11月
2008年10月
2008年09月
2008年08月
2008年07月
2008年06月
2008年05月
2008年04月
2008年03月
2008年02月
2008年01月
2007年12月
2007年10月
2007年09月
2007年07月
2007年06月
2007年03月
2006年12月
2006年11月
2006年05月
2006年04月
RECENT ENTRY
国立大学職員日記:記事一覧
国立大学事務職員の年収(勤続1年目~8年目)+席次の推移
平成26年4月1日付け大学教員任期法等の改正(労働契約法の特例)について
国立大学事務職員の年収(勤続1年目~7年目)
資料編その2:国家公務員I種 省庁別採用者内訳(平成23年度)
資料編その1:国家公務員I種 大学・学部等別採用者内訳(平成23年度)
国家公務員I種採用者の出身大学ランキング(平成23年度)
改正労働契約法で国立大学の非正規雇用はどう変わるか?(「教育・研究系非常勤職員」編)
改正労働契約法で国立大学の非正規雇用はどう変わるか?(「非常勤職員」編 その1)
昇給、その評価方法について
RECENT COMMENT
”センター”の公募にご用心!!/
国立大学職員日記:記事一覧
Unknown/
国立大学職員日記:記事一覧
replica handbags/
平成23年度 運営費交付金 国立大学ランキング
gucci replica/
「旅費」における「支度料」について
nike air max outlet/
平成23年度「期末手当」「勤勉手当」情報 + 「役職段階別加算」と「管理職加算」について
replica handbags/
「寒冷地手当」について
fendi outlet/
平成24年4月1日時点における若年層の号俸回復状況+前後数年の基本給金額推移
cheap football shirts/
国立大学は震災復興特別会計をどう使ったか?
nike air max outlet/
平成24年6月「期末手当」「勤勉手当」情報 + 国家公務員給与削減法の影響について
michael kors replica/
平成22年度 国立大学病院看護師「平均年収・人数」等の一覧
CATEGORY
国立大学職員日記
(147)
BOOKMARK
大学職員.net -Blog/News-
公務員試験コミュニティ
5号館のつぶやき
SEARCH
このブログ内で
ウェブ全て
平成23年度科学研究費補助金ランキング
国立大学職員日記
/
2011-07-01 07:00:00
■はじめに
旅費の処理をやっていると「この出張、新しく採った科研費で行きたいんだけど申請はいつから出来るの?」と教員から聞かれるのはもはや毎年の「お約束」イベントです。
そんな訳で文部科学省科学研究費補助金のランキングを今年も作成してみました。「PDF→テキスト→エクセルの文字列関数でデータ抽出」という相変わらず進歩の無い作業で作ったデータのため、例のごとくどこかにデータ間違いがある可能性が高いです。そこらへんは個人でやっているブログの限界ということでどうかご容赦いただき、関係機関の皆様には話のネタにでもしていただければ幸いです。
今年度は「平成23年度」のものの他にも、国立大学が法人化した平成16年度からの8年分をまとめたランキングも作ってみました。
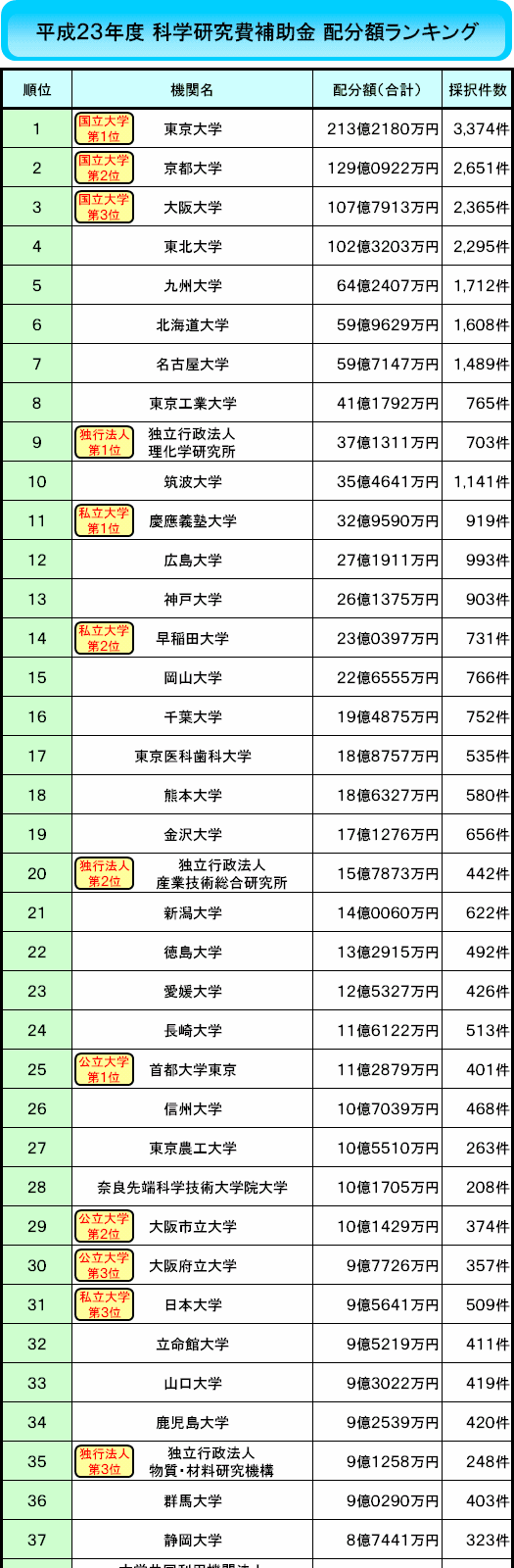
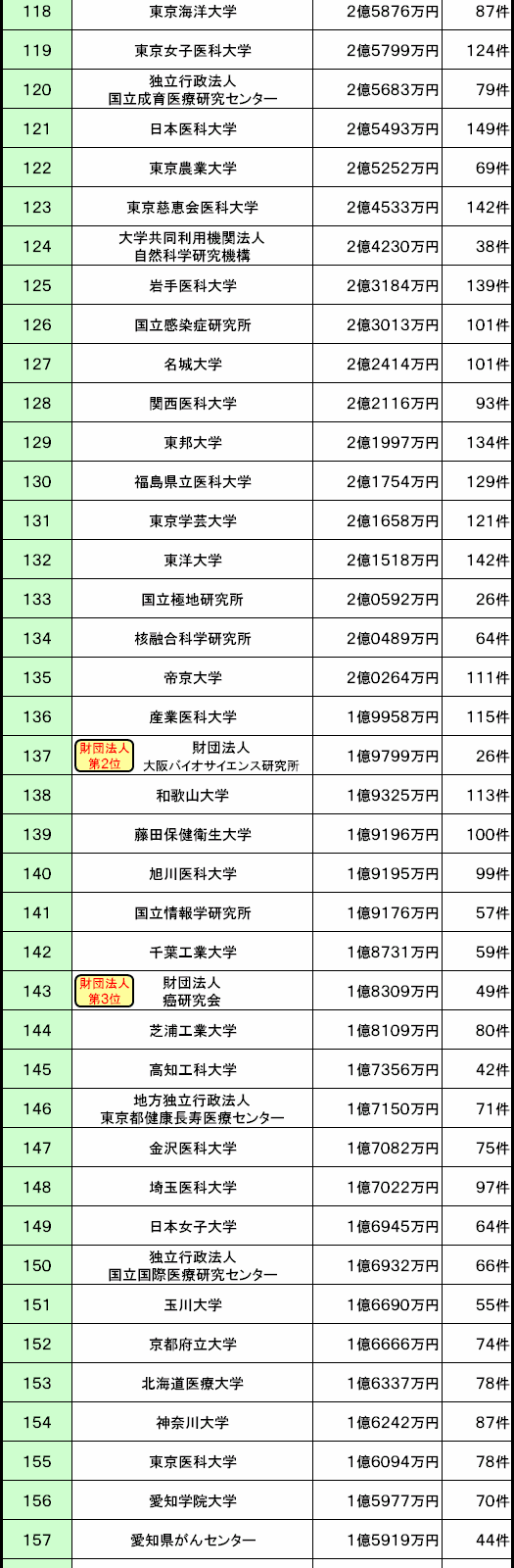
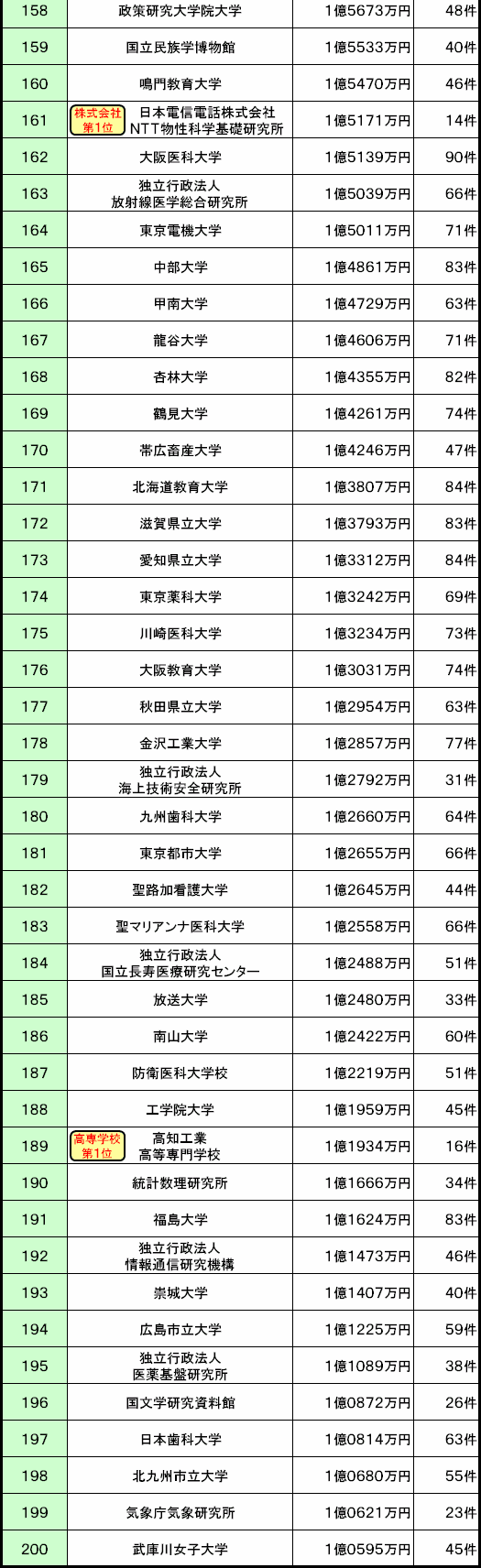
■平成23年度 科学研究費補助金 配分額ランキング
ランキングは「配分額(合計)」の順位で作成し、各機関カテゴリーの上位3位まで、別に順位表示をさせています。
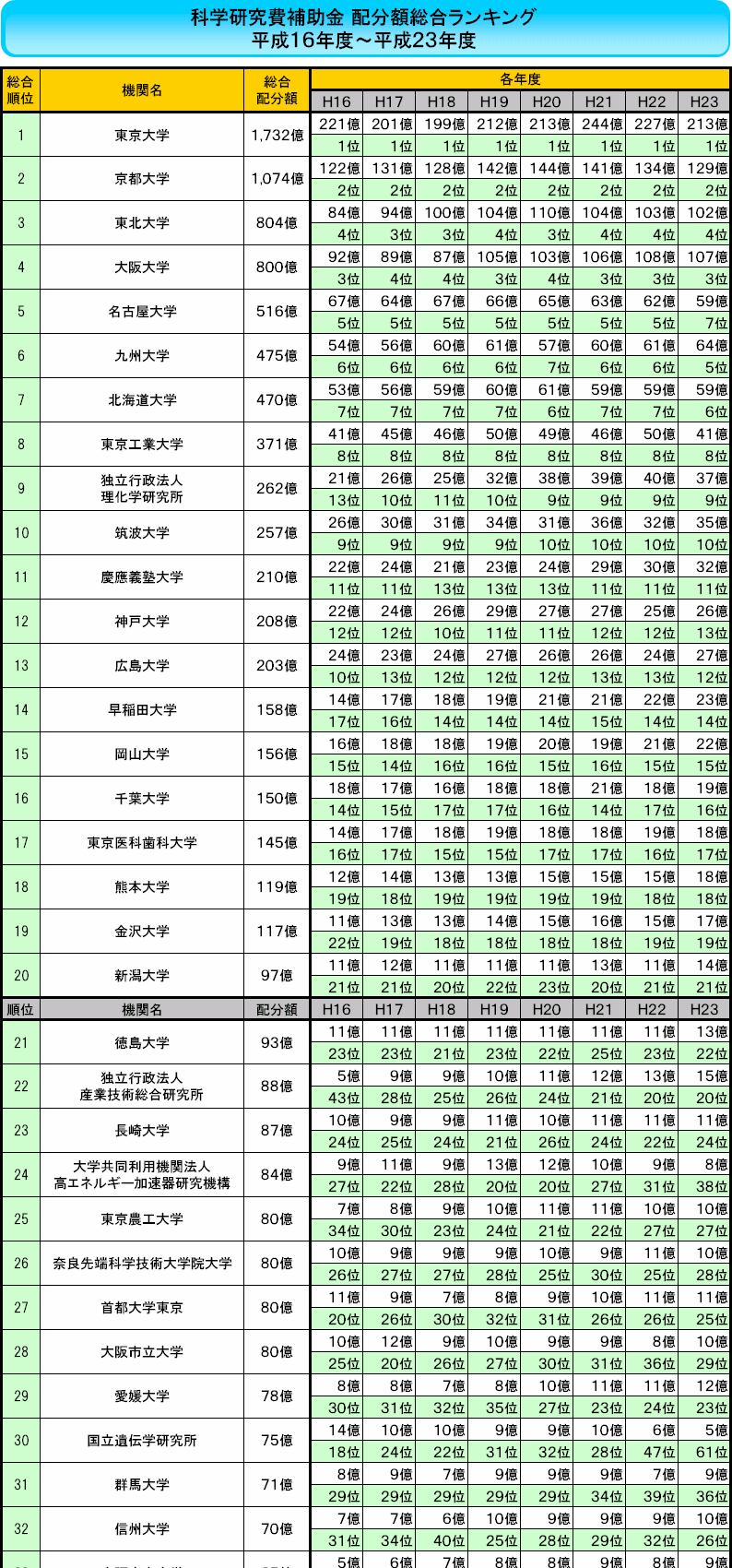
■科学研究費補助金 配分額総合ランキング 平成16年度~平成23年度
「総合ランキング」は平成16年度から平成23年度までの「配分額(合計)」の合計金額にて順位付けし、上位100機関の過去8年分の金額と順位の推移をまとめました。表示している金額は億で端数切捨てしてあります。「新規採択+継続分」のデータであることをご注意ください。
■総合ランキング上位20位の順位変動グラフ
これは総合ランキングで上位20位だった機関の、8年間の順位変動をまとめたグラフです。さすが競争的資金だけあって、運営費交付金に比べると順位変動が多いのが分かります。しかし同時に、我々はこのグラフからあるグループの存在と、それを隔てる「壁」の存在に容易に気づくことが出来ます。ここまで綺麗に分かれたのは恐らく偶然だと思いますが、それでも8年間に渡って存在しているので、ある程度の法則性はあるのだと思います。ちょっと面白かったので、文章で次のとおりにまとめてみました。
【科学研究費補助金獲得状況】
首席:東京大学
次席:京都大学
3位決定戦:大阪大学vs東北大学
準々決勝組:九州大学vs北海道大学vs名古屋大学
---旧帝国大学の壁---
東京工業大学
---上位安定組の壁---
理化学研究所vs筑波大学vs慶應義塾大学vs広島大学vs神戸大学
---13位の壁---
早稲田大学vs岡山大学vs千葉大学vs東京医科歯科大学
---17位の壁(以下、乱戦)---
■おわりに
自分は相変わらず総務系統の部署にいますが、科学研究費に限らず、外部資金や競争的資金の獲得にいかに教員が苦戦しているか、徐々に分かり始めてきた気がします。金をかければ良いというものでは無いでしょうが、「無料で手に入る情報には所詮限界がある」というのもまた事実だと思います。当ブログですら資料収集に金が掛かっているのですから、それを生業とする研究者が必要とする資金の多さは「想像に難くない」というやつです。
あと全然関係ない話なんですが、例えば自分のような人間も科学研究費補助金をもらうことが出来るのだろうかと疑問に思ったのですが、実際どうなんでしょうか。そんな大した額はいらないですが、課題名「産学官連携状況から考える国立大学における非常勤職員雇い止めの問題点」で、書籍代を10万円もいただければ、1年以内にこの問題についてまとまった意見を書いてそれをこのブログで公開することが出来ると思います。
まぁこの話はほとんど冗談みたいなものですが、実は過去に国立大学事務職員であっても科研費を獲得した例があるので、そこまで荒唐無稽な話とも言い切れないのが面白いところなのです。研究には金が掛かりますが、夢を見るだけなら無料ですからね。いつか科研費もらえたらいいなぁ~とか考えて、今日も自腹で資料収集する訳ですよ。
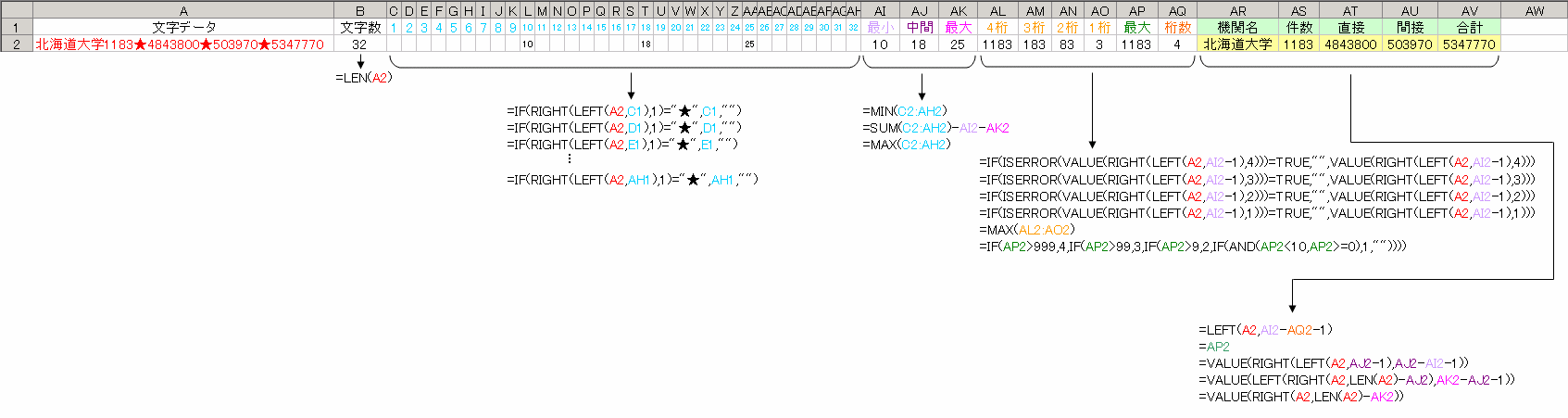
※おまけ:PDFからエクセルへデータを抽出する方法
必ず手作業が入るので、プロの方(いるのだろうか?)がされているやり方などには及びませんが、このやり方なら毎年公表されているデータを数分程度で9.5割方データ化できるので、参考までに残しておきます。
1.PDFファイルの準備
科学研究費補助金のデータは学術振興会のサイトから手に入ります。以下の方法は学術振興会が公表しているPDFファイルでのみ有効ですので、参考にする場合は必ず学術振興会のPDFファイルを参照してください。
2.PDF→テキストデータ
PDFファイルを「全て選択」し、テキストエディタ上にテキストデータを貼り付けてください。必要な部分だけを選択しても良いのですが、どうも経験上「全て選択」して後から不要な部分を切り捨てるほうがうまく行っているので、個人的には「全て選択」を推奨します。なお、自分が使っているテキストエディタソフトは「TeraPad」です。
3.ヘッダーや題名などの、不要な情報の削除
「全て選択」で貼り付けたデータには不要な部分が多いので、まずそれらを取り除きます。
文書のヘッダーや題名部分は手作業で取り除きますが、データ部分は手作業でいじらないでください(データ部分の編集作業は後述)。この作業で、とりあえず「データ部分」だけが残るようにします(早い話が「北海道大学」から「株式会社林原生物化学研究所類人猿研究センター」までの部分)。
4.データ部分の整理(テキストエディタ)
まず「置換」機能を使って「,(コンマ)」を全て消してください。
次に「 (空白)」をなんでもいいから特殊な記号に置換してください(自分は「★」に置換します)。
こうすることで「(機関名)(採択件数)★(直接経費)★(間接経費)★(合計額)」のデータが残ります。「機関名」と「採択件数」の間に「★」は入らないので、「北海道大学1000」みたいな状態になります。
また年度によっては片括弧の「)」に空白がついて「)★」みたいな状態になるので、「)★」を「)」に置換しておくと後で作業が楽になります。
5.データ部分の整理(エクセル)
ここを詳細に書くと何万字も掛かるため、要点だけを記します。
使う関数は「LEFT関数」「RIGHT関数」「MIN関数」「MAX関数」「LEN関数」「ISERROR関数」「IF関数」「AND関数」です。
まず「文字データ」の何文字目に「★」があるかを調べてください。例えば10文字目に「★」があるかをチェックするために、「文字データの左10文字の一番右の文字が「★」だったら「10」を出力しろ」というような命令で「=IF(RIGHT(LEFT(文字データ,10),1)="★",10,0)」という風に作ります。実際には「10」の部分は「10」と入力されたセルを参照するように書きますが。
「★」は各「文字データ」に3つあるはずなので、その「最大値」「中間値」「最小値」を出してください。
次にこれらの値と関数を組みまわせて、「文字データ」から「★」に囲まれている部分のデータを抜き出してください。例えば右から2番目の「★(中間値)」と右から1番目の「★(最大値)」に囲まれたデータを採る関数は「=VALUE(LEFT(RIGHT(文字データ,LEN(文字データ)-中間値),最大値-中間値-1))」です。両端のデータの抜き方は簡単だと思うので省略します。
一番左のデータだけ「○○大学1000」みたくなっていますが、この数字部分は「採択件数」なので、どんなに多くても4桁どまりです。そのため、この部分の「右4文字」「右3文字」「右2文字」「右1文字」から数値を抜く関数を作って、その最大値を取るようにしてやれば自動的に数字が抜けることになります(「ISERROR関数」を使うとエラー表示部分を空白に出来るので便利です)。「機関名」はそうやって抜いた数値の桁数を、この「○○大学1000」の文字数から引いて、その数字をつかって「LEFT関数」で「機関名」を抜いてください。
6.おわり
これで「機関名」「採択件数」「直接経費」「間接経費」「合計額」のデータが抜くことが出来ます。いちどセルにデータを入れておけば、文字データ部分に値を挿入するだけで自動的に計算が出来るので便利です。
文字だけで記すとすごくややこしいですが、自分で作りながらやるとすんなり頭に入ると思いますので、もしよろしければエクセルの練習なんかも兼ねて挑戦してみてください。
参考:
平成23年度のPDFファイル
コメント (
19
)
|
Trackback ( 0 )
goo ブログ
編集画面にログイン
国立大学職員外伝020
平成25年4月から更新していないにも関わらず、同年12月時点でもアクセスいただいている方が結構いて、非常に申し訳ない限りです。
ちなみに更新をせずに何をしているかというと、英語の勉強をしています。
当初は日本語を話せない外国人招へい研究者の手助けにでもなれば、という程度だったのですが、勉強し始めてみると意外に業務上で役立つことが多く、少し形になるまで頑張ってみようと途中から本腰を入れ始めました。
このブログにはいつかまた(あるいはたまに)戻ってこようと思っておりますので、それまで気長にお待ちいただけましたら幸いです。
(平成25年冬至 記)
国立大学職員外伝019
いつの頃からか観光客と一緒に観光地を撮影するのが旅先での定番になりました。
元々は被写体に人物が欲しい際の苦肉の策だったのですが、妙に旅風情を残す画像が多く、そのうち意識して撮影するようになったものです。
肖像権に配慮して全員遠目の後姿なのが玉にきずですが、考えてみれば普段の自分の人間関係も大体そんな感じなので、まぁいいかなと思っています。
国立大学職員外伝018
バイクを運転していると昔よく聴いた曲がなぜか勝手に頭に浮かんできます。
ただあまりに久々なので歌詞がよく思い出せず、とりあえず後で聴きなおそうと思うのですが帰宅すると今度は何の曲だったかが思い出せません。
国立大学職員外伝017
自分はよく昼寝をします。
出勤日も昼休みは寝ますし、休日も午前中に2時間は寝ますし、ツーリング先でも眠くなったら道路脇の駐車帯にバイクを停めてそのまま寝てしまいます。
傍からはやたら寝るのが好きな人間に見えるかも知れませんが、実際は眠いときに動くと非効率的なので生産性を上げるために寝てるだけです。
決して寝ることが大好きとかそういう訳ではありません。
夜も毎日8時間くらい寝てますが、寝ることが大好きとかそういう訳ではないんです。
国立大学職員外伝016
ここ数年、旅先で見かけた野の花を撮影し、帰宅後にその名称を調べたりしています。
我ながら「親父臭いことしてるなぁ」とは思うのですが、これが思いのほか楽しくてやめられません。
この分だと庭に盆栽を並べだすのもさほど遠い未来ではないと思います。
国立大学職員外伝015
徒歩通勤をしているので、毎日最低7kmは歩きます。
この間「頑張れば1日20kmくらい歩けるんじゃないだろうか?」と思ったので休日に挑戦してみました。
普通に歩けました。
次は40km歩いてみます。
国立大学職員外伝013
何だかんだ言って自炊してます。しかしレパートリーがさっぱり増えず、気に入ったメニューを美味しくすることだけに専念しがちです。
こういうやり方じゃいまいち料理の腕も上がらない気がするのですが、とりあえず好物の餃子はとても美味しく作れるようになったので「まぁいいか」と思って餃子ばっかり食べています。
国立大学職員外伝011
相変わらず就寝前にホットミルクを飲み続けています。この前計算してみたら1年間で120Lの牛乳を飲んでいることが判明しました(1人で)。
ちなみにりんごは360個、ヨーグルトは28kg、納豆は22kgでした。多分、青魚も100匹くらい食べてます。
健康うんぬん以前に、こんなに毎日同じものばかり食べていて大丈夫だろうかと、たまに心配になったりします。
国立大学職員外伝010
一人暮らしも5年目になるとかなり自由気ままです。
休日の朝にふとコロッケが食べたくなったので午前中に本屋で料理の本を買って午後にホームセンターで揚げ物用の鍋を買って夕方に調理して夜に一人舌鼓を打つとか、そのくらい自由気ままです。
国立大学職員外伝005
デジカメの画像フォルダを見直してみるとたまに「あれ、こんなのあったんだ」という画像に出会います。上の画像はそんな中の一枚。動物を撮るのが苦手な割には上手に撮れてるつもりです。