








状態遷移の全てをここで語るにはスペースが狭すぎます。それなのに構造化設計の書籍はオブジェクト指向のそれに駆逐されてしまいました。状態遷移を専門に扱った書籍も見つかりませんし、オブジェクト指向の書籍に書かれている内容は物足りません。ここは少し解説しなければならないでしょう。
オブジェクトは状態を持っています。オブジェクトはメッセージを受信すると、イベントを発生し、結果として状態が変化したりしなかったりします。具体的にはメソッドが呼び出されると、状態に応じた処理をして、状態を変更して処理を終えます。
イメージしにくいでしょうか? 一見は百聞にしかずと言いますから、とりあえず下の図表を見てください。
|
|
停止状態 | 再生状態 | ポーズ状態 |
| 停止 | 無視 | →停止状態 | →停止状態 |
| 再生 | 再生を開始 →再生状態 |
再生を中断 →ポーズ状態 |
再生を再開 →再生状態 |
状態遷移表
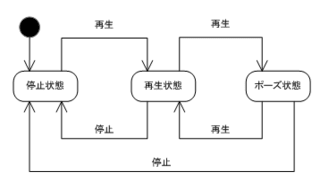
ステートチャート図(UML)
再生ボタンと停止ボタンしかない単純なCDプレイヤーです。ちょっとした機能として、再生中は再生ボタンがポーズボタンとして機能するようになっています。縦軸(黄色)はイベント、横軸(赤)は状態、青は処理を表しています。処理が終了すると矢印で示される状態に遷移します。例えば再生状態にあるときに再生イベントが発生すると、再生を中断してポーズ状態へ遷移することがわかります。再び再生が始まったりするようなことは無いわけです。
このように単純な例なら簡単ですが、複雑になってくるとすぐに破綻してしまいます。そういう複雑な状態遷移は状態をネストして解決します(下図)。状態のネスト、状態の入れ子、サブ状態などと呼ばれています。
| オープン | クローズ | |||
| 停止 | 再生 | ポーズ | ||
| 開 | 無視 | 開ける →オープン |
開ける →オープン |
開ける →オープン |
| 閉 | 閉じる →クローズ |
無視 | 無視 | 無視 |
| 再生 | 閉じて再生 →クローズ |
再生を開始 →再生(CDあり) |
再生を中断 →ポーズ |
再生を再開 →再生 |
| 停止 | 無視 | 無視 | →停止 | →停止 |
状態遷移表
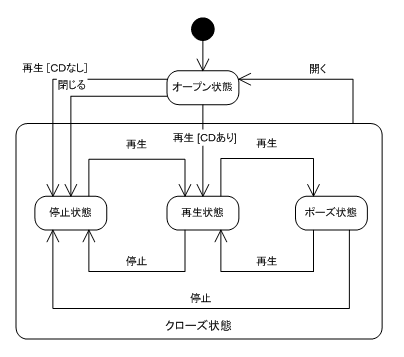
ステートチャート図(UML)
入れ子をどんどん深くしていけばもっと複雑な状態も表せるのですが、あまり深くなりすぎるようならオブジェクトが大きすぎるのかもしれません。
図表を作成することで、各状態における処理を洗い出すことができることが解ったと思います。ところがいざこれをコーディングしようとすると、意外にもなかなか難しいのです。
複数の状態を管理してイベント発生時に適切な関数を呼び出すように管理するために、ややこしいフレームワークを書いて、関数テーブルを作成しなければなりません。こうした手間を軽減するためにCASEツールを用いる方法もあります。状態遷移に対応したCASEツールならば、状態やイベントの追加も簡単ですし、どの状態のどのイベントがテストされていないといったような情報を集めることもできます。
ところで状態遷移とオブジェクト指向の関連性はどうなっているのでしょうか? オブジェクト指向ではオブジェクトが状態を持ちます。古くからある状態遷移表を用いる設計では表がたいへん大きくなります。携帯電話機などでは、なんと全てのイベントを一つの表にまとめたりします。しかし、オブジェクトはシステムやモジュールといった単位と比べると極めて小さく、あまり大きな遷移表を作ることはないと思います。また記述方式も表だけでなく、状態のネストを視覚的に表現できるUMLのステートチャート(上の図を参照)を用いるのが流行しています。イベントはメッセージと結び付けられ、まるでオブジェクト指向のためにあつらえたかのようにピッタリとあてはまります。
さて、あとはこれをコーディングするだけなのですが……。C++では状態をどのように記述するべきなのでしょうか? 古くからあるフレームワークを使うのも一つの手ですが、せっかくですからクラスを活用したいですよね。デザインパターンの本にあるステートパターンはどうでしょうか。これは各状態ごとに一つのクラスを設けるという、たいへん重装備なものです。はっきり言ってしまえば、普通はこんなものは使いません。オブジェクトの状態遷移をコーディングする方法はもっと単純なものです。
class CPlayer
{
public:
enum eState {
STOP, PLAY, PAUSE
};
private:
enum eState m_eState;
public:
CPlayer() : m_eState(STOP) {}
Play();
Stop();
};CPlayer::Play() {
switch(m_eState) {
case STOP:
cd_seek(TOP);
cd_play();
m_eState = PLAY;
break;
case PLAY:
cd_pause();
m_eState = PAUSE;
break;
case PAUSE:
cd_play();
m_eState = PLAY;
break;
}
}
CPlayer::Stop() {
if (m_eState != STOP)
cd_stop();
m_eState = STOP;
}
上記のソースは、最初のCDプレイヤーをコーディングしたものです。拍子抜けするほどに簡単ですね。イベントは関数で、状態はm_eState変数で表されていることが解るでしょうか。
気をつけて読んで欲しいのは、イベントの中で状態による処理を振り分けているところです。状態でswitchするのがカッコ悪いと思う人もいるかもしれません。しかしそれは本質的な問題ではありません。大切なのは状態遷移を忠実にコーディングできているかどうかであって、それができるのなら実装方法は何でもいいのです。
よく状態遷移ベースのCASEツールに影響されて関数ポインタの2次元配列でマトリックスを作りたがる人がいます。しかしながらクラスというものには適度なサイズというものがあり、適度なサイズのクラスは上記のサンプル程度のコードでよいのです。マトリックスが必要なら、その前にクラスが巨大すぎるのではないかということを疑うべきです。
またデザインパターンのステートパターンも不要です。オブジェクト指向がわかってくるとステートパターンの設計は誰でも直感的に思いつくでしょう。しかしステート間での情報共有は非常にややこしくならざるを得ず、全てのステートの組み合わせが1つのクラスであると考えれば、これもまたクラスが巨大すぎることを疑わせます。
関数ポインタマトリックスとステートパターンの2大設計が、クラス設計時の状態遷移設計の理解と普及の妨げになっているのです。
class CPlayer
{
public:
enum ePlayState {
STOP, PLAY, PAUSE
};
enum eTrayState {
OPEN, CLOSE
}
private:
enum eTrayState m_eTrayState;
enum ePlayState m_ePlayState;
public:
CPlayer() : m_eTrayState(CLOSE), m_ePlayState(STOP) {}
Open();
Close();
Play();
Stop();
};
CPlayer::Open() {
if (m_eTrayState == CLOSE)
cd_open();
}
CPlayer::Close() {
if (m_eTrayState == OPEN) {
cd_close();
m_eTrayState = CLOSE;
m_ePlayState = STOP;
}
}
CPlayer::Play() {
if (m_eTrayState == OPEN) {
Close();
Play();
} else {
switch(m_ePlayState) {
case STOP:
if (cd_exists()) {
cd_seek(TOP);
cd_play();
m_ePlayState = PLAY;
}
break;
case PLAY:
cd_pause(TRUE);
m_ePlayState = PAUSE;
break;
case PAUSE:
cd_pause(FALSE);
m_ePlayState = PLAY;
break;
}
}
}
CPlayer::Stop() {
if (m_eTrayState == CLOSE && m_ePlayState != STOP) {
cd_stop();
m_ePlayState = STOP;
}
}
状態がネストしている場合は、状態変数が別になります。大状態と小状態がしっかり別の変数になっていることに注意してください。その他の具体的なコーディングに目を奪われずに、状態とイベントが状態遷移表のごとく格子状に交差していることを理解してください。
状態の遷移を組むとき、状態変数を作っただけで満足してはいけません。イベントと状態がごっちゃになるミスを犯さないようにしなければいけません。また状態のネストを見極めて、大状態と小状態を一つの状態変数で管理してしまうことがないようにしなければなりません。
これらのミスはオブジェクトのコーディングを不必要に複雑化させ、たちの悪いバグを引き起こす原因になります。状態変数が受け持つ状態の範囲が適切かどうかは、状態遷移表やステートチャート図を書くことで判断できます。頭の中で整理したつもりでも、図表を書いてみると、簡単な間違いが残っていることに気づかされるものです。
状態遷移を分析するということはオブジェクトが状態変数を持つというような単純な話ではないのです。下手な設計ですと、コードはかけても図は汚くなります。状態変数の数や役目が適切かどうか、イベントとの対応が適切かどうかを、図や表を用いて視覚的に判断するという話だったわけです。
ところで今回の例には含まれていませんが、状態にはヒストリ(履歴)という概念があります。以前の状態を記憶しておくことがあるのです。例えば、メニューを開きなおしたときに、カーソルの位置が前回開いていた位置を指しているような場合を想像してください。こうしたことを実現するために複雑なコーディングをする必要はありません。大状態と小状態がきちんと別の変数で管理されていれば、状態変数を初期化するかどうかを切り替えるだけで、他には何の工夫もなく自然と実現できるのです。
というわけで、ざっと簡単に状態遷移を解説してきましたがいかがでしょうか。状態遷移を整理すればオブジェクトの振る舞いを面白いほど簡単に実装できます。世の中には状態遷移の魅力に麻薬のように取り付かれた人たちがいるほどです。この世界はまだまだ奥が深いので、いろいろ検索してみると面白いですよ。