〇 Webサイトの閲覧は、インターネットの重要な用途だ。それを実現する仕組みをWWWと言う。今回はWWWを支える3つの技術を解説する。
インターネットでWebサイトを閲覧できる仕組みをWorld Wide Webと言う。略してWWW、もしくはWebと呼ぶことも多い。
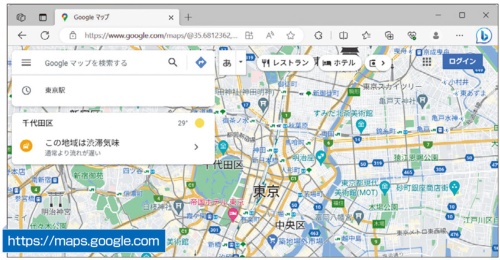
WWWの特徴は、ページ中のリンクをクリックすると別のページにジャンプする仕組みを持つこと。これにより、世界中のWebサイトにある情報を、次々とジャンプしながら参照できる世界が実現した(図1)。
このようにテキスト間をジャンプできる仕組みをハイパーテキスト(HyperText)と呼ぶ。WWWはインターネットでハイパーテキストを実現する仕組みだ。もっとも、現在のWWWでは、テキスト(文書)だけでなく、画像や映像、音声など、文字以外の情報にもアクセスできるし、買い物などのサービスも受けられる。さらに、Webサイトがアプリのように動作することもある。WWWは、より広い領域をカバーする、インターネットの技術基盤になっていると言える。
情報の所在を指すURL。
そんなWWWを支える基本的な技術は3つある。URL、HTTP、HTMLだ(図2)。HTTPやHTMLの名称にHyperTextが含まれていることからも、WWWの成立にハイパーテキストの機能がいかに重要だったかが分かる。

URLは、インターネット上のデータやサービスの所在を特定する文字列で、一般には(Webサイトの)「アドレス」として認識されることが多い。厳密には、インターネット上でリソースを特定する名前を指すURN(Uniform Resource Name)とセットで、URI(Uniform Resource Identifier)と呼ばれるのだが、本講座ではなじみのあるURLで統一する。
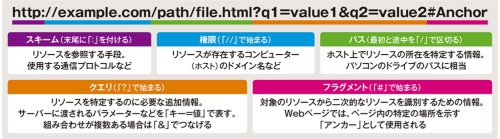
URLの基本的な構造を図3に示す。スキーム、権限、パス、クエリ、フラグメントの順に情報が並ぶ。Webサイトへのアクセスでは、権限に当たるドメイン名以降を省略できることもあるが、その際にはサーバー側の処理で適切なページが提供されている。
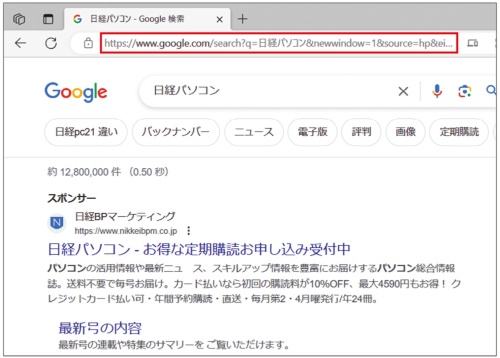
パスの後の「?」で始まるクエリは、Web検索時の検索結果のページのURLとして目にする機会が多い(図4)。ちなみに、図4のURLに含まれる「日経パソコン」の語句は、実際には英数記号に変換(エンコード)されているが、Webブラウザーが日本語表記で表示している。
スキームは多種多様。
URLの先頭に入るスキームは、Webサイトの利用では通信プロトコルを指すhttpか、http通信の暗号を指定するhttpsが入るのが普通だ。しかし、URLで指定可能なスキームはかなりバリエーションが広い(図5)。

分かりやすいところでは、パソコンにダウンロードしたPDFファイルをWebブラウザーで開くケースがある。URLのスキームは「file」で、権限が省略されて「///」という表記になり、PDFファイルのパス(ドライブ、フォルダー、ファイル名)が続く。
Webブラウザーでは、ファイル転送専用のプロトコルのFTPを利用して、FTPサーバーとファイルを送受信することもあった。しかし、最近はセキュリティ上のリスクを避けるため、「Edge」や「Chrome」などではこの機能が削除されている。
特殊なスキームとしては、メールアドレスを指定するmailtoや、電話番号を指定するtelがある。Webサイトに書かれたメールアドレスをクリックすると、メールアプリの新規メッセージ作成画面が開いたり、スマートフォンでページ中の電話番号をタップすると電話をかけられたりするのは、これらのスキームをWebブラウザーが処理してほかのアプリに制御を渡した結果だ。EdgeやChromeなどのアドレスバーに、「mailto:(メールアドレス)」と入力して、動作を実験することもできる(図6)。
EdgeやChromeは、Webブラウザーが自分自身の情報を表示するために独自のスキームを利用している(図7)。Edgeでは「edge」、Chromeでは「chrome」が使われている。両アプリで設定画面を開くと、URLが割り当てられていることが分かる。どちらのアプリでも、URLとして「(Webブラウザー名)://flags」を開くと、通常の操作ではアクセスできない、試験段階の機能をオン/オフする画面が表示される(図8)。どちらのアプリもオープンソースプロジェクトの「Chromium」をベースに開発されていることによる共通点だろう。
HTTPでデータを取得。
パソコンやスマートフォンといったユーザー側の端末(クライアント)がWebサーバーからデータを受け取る通信プロトコルには、専用の規格である「HTTP」が利用されている。スキームの「http」はこれだ。一方、通信を暗号化するスキームは「https」だが、こちらはプロトコルの名前ではない。httpの通信を、ほかの規格を組み合わせてセキュア(Secure/安全)に行うという指定だ。その仕組みについては、別の回で取り上げる。
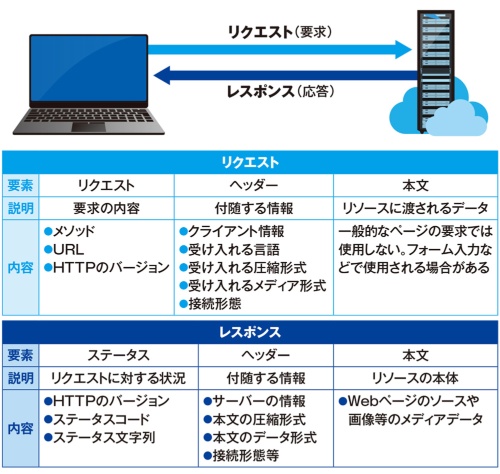
HTTPによる通信は、サーバーに対するリクエスト(要求)と、それに対するサーバーのレスポンス(応答)によって実行される(図9)。リクエストとレスポンスには、それぞれ図9のような情報が含まれる。
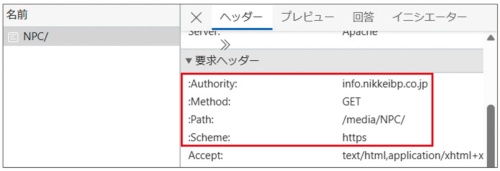
リクエストのメソッドに、図3のURLの書式で示した「#」で始まるフラグメントは含まれない。フラグメントの情報は、Webページだとページの途中に表示位置を移動する目印(アンカー)として利用されるが、Webブラウザー側で処理が完結するため、サーバーには送信されないからだ。
サーバーからの応答にある「ステータスコード」は、リクエストに対する処理結果を示す情報で、3桁の数字で示される。間違ったURLを開こうとして、ときどき「404. not find」などの表示を見ることがある。この「404」などがステータスコードだ。
Webブラウザーで情報を見る。
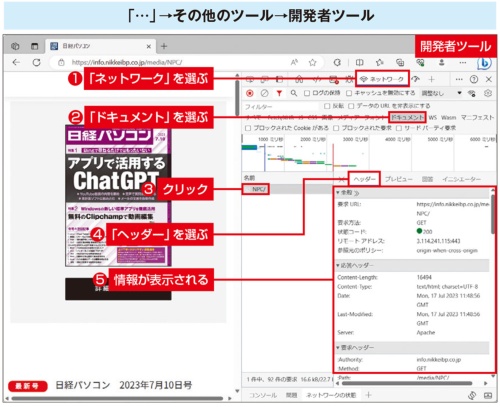
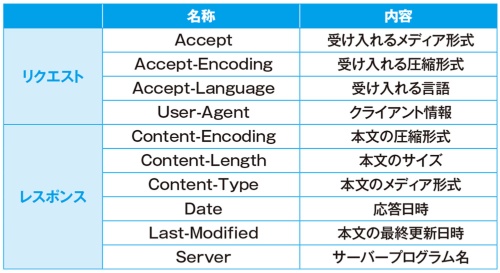
EdgeやChromeでは、アプリに内蔵されている「開発者ツール」という機能を使って、WebブラウザーとWebサーバーとの通信内容をのぞき見できる(図10)。開発者ツールで「ネットワーク」の情報として「ヘッダー」を選ぶことで、メソッドなどを含む通信内容の概要が分かる(図11)。ヘッダーにはいろいろな種類がある。主なヘッダーの説明を図12に示す。
HTTPには複数のバージョンがある。初期のHTTP/1.0は、1つのリソースを取得するたびに接続の確立と切断が必要で、通信効率が悪かった(図13)。しかし、HTTP/1.1で一度確立した接続を複数のリソースを取得するのに使えるようになった。
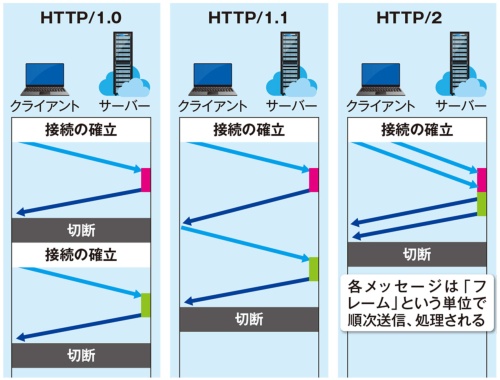
後継のHTTP/2では、リクエストの順番に影響されず、並行して複数の通信ができるようになった。さらに、HTTP/1.1までは、通信の内容を人間が読めるテキスト情報(プレーンテキスト)で送っていたが、HTTP/2はコンピューターでの処理に適したバイナリー形式を使う方式となり、効率的な通信が可能となった。
さらに、2022年には最新バージョンのHTTP/3が正式な規格として成立した。これまでTCP上でなされていた通信を、UDPで行う形式に改めるなどして、より高速な通信を実現している。米グーグルの主導で開発された規格だ。EdgeやChromeなど、主要なWebブラウザーは既に対応済みであり、サーバー側の対応が進めば、Webの利用がさらに快適になりそうだ。
ページを表現するHTML。
Webブラウザーに表示されるページの内容は、HTMLという規格のデータで表現される。データの実体は文字のみのプレーンテキストだが、本文などの文章だけでなく、ページのレイアウトなどの多くの情報も一定の表記ルールで書かれている。Webブラウザーは、受信したデータを解釈して、指示されたように描画しているのだ。
このように、本文と一緒にテキストで付加情報を記述するルールをマークアップ言語(ランゲージ)と言う。HTMLは、「ハイパーテキストを記述するマークアップ言語」という意味だ。開発者ツールを使うと、現在表示しているページの元データ(ソース)を見ることができる(図14)。ソース中で「<」と「>」に挟まれているのが、タグと呼ばれる付加情報だ。
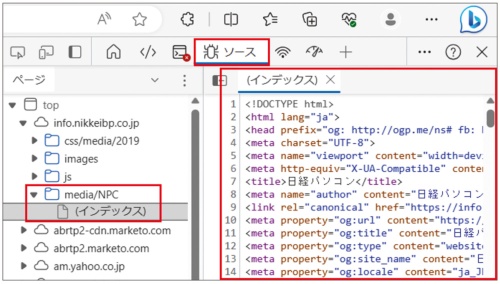
写真や音声など文字以外のデータは、ページのソースには含まれていない。別のリソースを読み込むよう指定されている(図15)。別のページを開く「リンク」もタグで設定されている。

現在のWWWでは、ページ内でデータを処理する簡易プログラミング言語であるJavaScriptなど、多くの周辺技術も標準規格で定められている。アプリのように動作するWebサイトは、こうした技術の組み合わせで実現されている(図16)。