








超久々の更新です。
PriMoreについて、コピペ不使用のアイディアを達也さんに頂いて
放置してしまっていましたが、達也さん自身が修正版を公開されました。
http://page.freett.com/t2255/PriMore.html
ソースを公開してよかった。。
と思って見たら私のソースの酷いこと、、
一念発起して、リファクタリングしてインストーラでも作ろう作業して
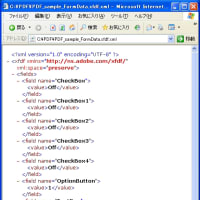
リファクタリングまでしたら、AdobeReaderで文書のプロパティが文字化けしてる!!
Foxitでは文字化けしてないし原因不明。
AdobeReder9まではうまくいっていたような気がしますが、10,11ではだめですね。
しおりについては文字化けしないんで、文章のタイトルとかの読み込みが
PDF自体の定義⇒XMPの順だったのが、XMP⇒PDF自体にかわったのかもしれませんね。
PDF自体の定義は、PDFDocEncodingで記載することで問題ないはずなんですが、
XMPにもそのままコピーされているので、これがまずい(今になって化けるようになった)原因かもしれませんね。
http://ghostscript.com/doc/current/Ps2pdf.htm
の
-sDSCEncoding=string
にそれらしいことが書いてありますが、PrimoPDFで、PS2pdfを直接叩いているわけじゃないのでよくわからない。。
BullZipでは問題ないの解決方法がありそうな気もしますが。。。
PriMoreについて、コピペ不使用のアイディアを達也さんに頂いて
放置してしまっていましたが、達也さん自身が修正版を公開されました。
http://page.freett.com/t2255/PriMore.html
ソースを公開してよかった。。
と思って見たら私のソースの酷いこと、、
一念発起して、リファクタリングしてインストーラでも作ろう作業して
リファクタリングまでしたら、AdobeReaderで文書のプロパティが文字化けしてる!!
Foxitでは文字化けしてないし原因不明。
AdobeReder9まではうまくいっていたような気がしますが、10,11ではだめですね。
しおりについては文字化けしないんで、文章のタイトルとかの読み込みが
PDF自体の定義⇒XMPの順だったのが、XMP⇒PDF自体にかわったのかもしれませんね。
PDF自体の定義は、PDFDocEncodingで記載することで問題ないはずなんですが、
XMPにもそのままコピーされているので、これがまずい(今になって化けるようになった)原因かもしれませんね。
http://ghostscript.com/doc/current/Ps2pdf.htm
の
-sDSCEncoding=string
にそれらしいことが書いてありますが、PrimoPDFで、PS2pdfを直接叩いているわけじゃないのでよくわからない。。
BullZipでは問題ないの解決方法がありそうな気もしますが。。。
ありがとうございます。
対応策としては、以下のサイトを参考に
二重起動だったらウェイトする感じですかね。
http://www.upken.jp/kb/vbscript-dedup-process.html
先日印刷であるバグが発生しました。ご報告致します。
現象として、連続印刷に置いて、先に内容の多いものに続いて、内容の少ないものを印刷すると、最初のものが無くなってしまいます。
ソースを拝見すると、多分一つ目の印刷処理でメインファイルを作成する前に2つ目の印刷処理が来てしまうからだと思われます。
メインファイルは作られている途中に、判定条件でもう一度メインファイルを作る処理に流れてしまうと思われます。
対策はまだ見当たりません。できることならばご教授願います。