
さて、あまりプログラミングのネタを取り扱ってるブログがないgooブログなワケなんですけど。
ちと検索したら最近Pythonをはじめた、と言うブログが引っかかった。これだ。
人気あるね、Python。
んで、この人が面白い事をやってた。これだ。
そして今度は手始めに、簡単な単振動のシミュレーションのプログラムを試作してみました。
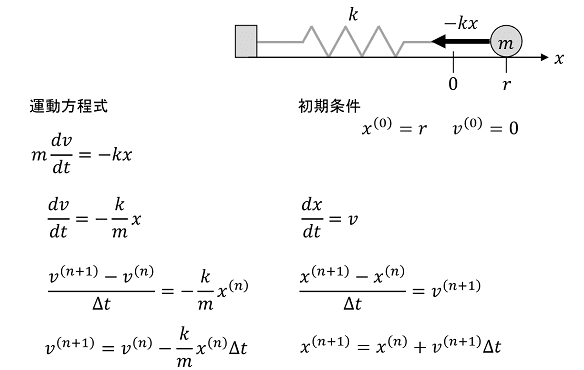
数学と言うより物理だな。懐かしい。
この人の方針は、直接微分方程式を解くんじゃなくって、差分方程式に直してグラフにしよう、って事をやってる。
詳しくはこの人のページで紹介してるフローチャートとスクリプトを見てみて欲しい。
上の差分方程式を見て、その数式で「ウゲ」って思うかもしれないけど、非常に丁寧に解説されている。そして結果は極めて単純だ。
さて、差分方程式、と厳つい名称で呼んでるが、要するにこれもまた単純には漸化式だ。漸化式と言えば再帰で、Lisp大好きっ子だとついついそのままプログラミングしちまうだろう。
ただし、式を見てみれば分かるけど、vはxを含み、xはvを含むんで、考え方は確かに再帰なんだけど、ちと複雑になっている。
こういうカタチでお互いに呼びあいつつ再帰するのをプログラミング用語で相互再帰と呼ぶ。
ところが、この問題の場合、まずはこの相互再帰が厄介なんだな。
Racketで直球勝負で書くと、例えば次のような大域変数定義と2つの式となるだろう。
(define-values (*m* *k* *dt*) (values 1 10 0.01))(define (v_ n_max)
(let loop((n 0) (v_n 0))
(if (> n n_max)
v_n
(loop (+ n 1) (- v_n (* (/ *k* *m*) (x_ (sub1 n)) *dt*))))))
(define (x_ n_max)
(let loop ((n 0) (x_n 1))
(if (> n n_max)
x_n
(loop (+ n 1) (+ x_n (* (v_ (sub1 n)) *dt*))))))
ところが、これじゃあ最適化が成されないんだ。何故なら末尾再帰としては不完全だ、と言う厄介な事が起きている。
どういう事なんだ。再帰関数のloopがキチンと末尾で呼び出されてるじゃねぇか、とか思うかも知れないけど、困った事にvがxを呼び出す、そしてxがvを呼び出すトコが末尾再帰になっていない。
従って、そこでの演算が面倒な事になって、結果末尾再帰として最適化が成されないんだ。
もう1つこの計算負荷が高い原因がある。例えばx_(3)を計算するにはv_(3)が必要になる。v_(3)を計算するにはx_(2)とv_(2)が必要になるわけだが、当然それらを求める為にはそこで一々再帰せねばならない。そこの計算が終わってx_(3)が求まった際にはそれらの計算結果は忘れ去られてしまう。そしてx_(3)が実はx_(4)で呼び出されていた際にはx_(3)の計算結果も当然消える。x_(5)を計算させてた際にはx_(4)とv_(5)をまたもや計算しなきゃならなく、その際にはx_(3)をまた計算して・・・と引数が大きければ大きい程、天文学的な回数の再帰計算が必要になってくるんだ。
多分、件のページのように500回も演算させようとすると、メモリを食い潰して止まってしまうだろう。それくらいこいつは厄介な計算となっている。
すわ、Lisp言語族の敗北か?と思うだろう。いや、まぁ違うけどね(笑)。
それはともかくとして、こういう「スゴい計算負荷がかかる」プログラミングと言うのは思いつこうとしてもなかなか思いつけないモンだ(笑)。そういう意味ではこれは良問であり、「遊び場」としてはサイコーのケースではあると思う。これを何とかしてやろう、とか挑戦する事がテクニックを鍛えるケースにもなるんだな。そして問題が単純だからこそ挑戦しやすい。
さて、こういう再帰が入り組んでいて、高い計算負荷がかかる場合、RacketやSchemeだとどうすりゃエエんだろう。実はこれらには言語仕様上、既に解決方法が提示されている。遅延評価だ。この例題は遅延評価を扱うべき、だと言う典型的なモデルケースになっている。
「遅延評価?怖いよ」とか言う人たちにとっては「マトモに再帰を書こうとしたら計算が高負荷なのに遅延評価だとアッサリと解ける」非常に明解な例となるだろう。
それはこう書く(※1)。
(require (only-in srfi/41 stream-map))(define-values (*m* *k* *dt*) (values 1 10 0.01))
(define *v*
(stream-cons 0
(stream-map (lambda (v x)
(- v (* (/ *k* *m*) x *dt*))) *v* *x*)))
(define *x*
(stream-cons 1
(stream-map (lambda (x v)
(+ x (* v *dt*))) *x* (stream-rest *v*))))
一瞬ちと見慣れない書き方に見えるが、良く見てみると、件の「計算負荷が高い」再帰と基本的には全く同じことをやってるのが分かると思う。しかもある意味間違いなく「相互再帰」だ。
いや、概念的には相互再帰ではあるんだけど、そうは見えない最大の理由は、件の「計算負荷が高い」相互再帰は関数なんだけど、こっちでは結果、全く関数が定義されてない。全部データになっている。そう、遅延評価を使って設問に適したデータを作ってる、と言うのが方針の大きな違いだ。
ちと詳細を見ていってみよう。
stream-consが行ってるのは初期値を追加してる事だ。*v*の場合は0がstream-consされ、*x*の場合は1がstream-consされている。前者は単振動での速度の初期値、後者は単振動の中心からの距離になっている。
両者ともすぐさまstream-mapが適用されている(と言うかそれが本体だ)が、フツーのmapと違ってこれが一番不可思議だろう。と言うのも、例えば*v*の場合、今定義途中の*v*を呼び出して再帰している。つまり現在存在しない筈のデータに対して再帰を仕掛けてるように見えるんだ。
しかし、良く考えてみると、これは遅延評価にとっては別に不思議じゃない、と言う事が分かるだろう。通常のプログラミング言語における先行評価(つまり関数が適用される前に引数が評価される)だと、「まずはデータが存在しないと」どうしようもない。何故なら引数はデータが入る場所なわけで、関数が適用される前にデータが存在しないとエラーとなってしまう。
反面、遅延評価の場合は、極端に言うと「関数の存在が確認されたあと」引数が評価される。つまり引数の評価は常に後回しなんで、現時点で引数に突っ込まれたデータが存在しようとしまいとどうでもいいんだ。そして遅延評価とは「実行が決定された時に必要に応じて引数が評価される」事なんで、言い換えると、これら*v*や*x*のように「定義途中の今、そのデータが存在しようとしまいとどーでも良い」評価戦略と言う事になる。従って先行評価に慣れてると一瞬「あれ?」と思う事になるんだが、実は全く問題はないんだ。遅延評価用に頭を切り替えていこう。
さて、*v*と*x*をもうちょっと見てみようか。これは極端な話今の時点でこうなっている。

nは要素番号、vとxはそれぞれ*v*、*x*の事だ。両方共stream-consで初期値、つまり、n = 0での値は決まってるが、それ以外は分からん、と言う事だ。
ここで、stream-mapが何をやってるのか、と言うとだ。例えば*v*に付いては。

つまり、*v*の各要素の「情報」は同じく*v*と*x*を利用した「計算式」によって埋められている、と言う事だ。*v*の第1要素は*v*の第0要素と*x*の第0要素を用いて定義され*v*の第2要素は*v*の第1要素と*x*の第1要素を用いて定義され・・・・・・と続いていく。永遠に、だ。
ここで重要なのは、先程にも書いた通り、遅延評価は「引数が必要になった時」実体化させる仕組みなんで、ここでは要するに「どこを参照しろ」と言う情報とそれを使った「計算式」しか定義してない事だ。要するに具体的な中身は全く存在しない。
しかし、一旦「実体化させろ」と言う命令を受け取ったら遅延評価はその計算を具体的に始める。トリガーは初期値であり、それを利用して次の値を生成、次は、またそこで生成された値を使って値を生成・・・と指定された限界まで「計算式を実行しながら」値を具現化していくわけだ。
上の再帰関数に対しての遅延評価の利点がもう1つある。あの再帰関数が重くてマトモに動かない相互再帰以外のもう1つの理由は、ある値を生成する為には別の値が必要になり、その別の値を計算させる為にはまた再帰を用いる、と言うのが強烈な負荷になってる、と言うモノだった。
一方、遅延評価の場合は、一旦値を生成すれば「そこに留まり続ける」(関数じゃなくってデータだし)。と言う事は、再帰版のような「ある要素を求める為の再計算」が全く必要ない、と言う事だ。新しい値を生成する際には「参照先をチラッと見れば」済む。つまり、再帰版で計算式の数学的な定義上、どうしても必要な「記述」が、遅延評価版だとそのまま記述しても「負荷」にならない、と言うオイシイ副次的効果があるんだ。
なお、*x*の方は次のように図示される。

定義式を見ると、計算結果である筈の*x*と*v*の「項番号」nは一致してる。ズレてるのは再帰的に用いられる*x*だけ、だ。具体的に言うと例えば、*x*の第一項を計算する際、再帰的に用いる*x*の要素は第0番目、だが、*v*の方は第一項なんだ。

従って、stream-mapを適用する際には*x*はそのままでいいが、*v*の先頭は削らないとならない。そのため、*v*にはstream-restを適用している。
さて、遅延評価を用いるのは、ちょっとしたアイディア(具体的にはstream-mapの使用法)は必要だが、やはり「数学的表現をそのまんま」プログラミング出来るのが大きくて、ハッキリ言ってラクだ。なんせ関数も定義してねぇし、データしか定義してない。
そして場合によっては通常我々が使ってる関数よりも高速に物事を成し遂げてくれる。
それを実感するにも単純な「数学的スクリプト」による実験、と言うのは極めて有効なんだ。っつーか「物凄く実験しやすい」。
数学的スクリプトを怖がるな。これ程簡単に色々改造出来て、色んなアイディアを試せる「材料」は実は他には存在しない。
さて、Racketでの締めくくりとしては、原作と同様にグラフのプロッティングをしてみよう。Racketのプロッティングモジュールはまんまplotと言い、ここではその細かい使い方は説明しないが、取り敢えず単振動のRacketの遅延評価を使ったスクリプトは次のようになる。
#lang racket
(require plot (only-in srfi/41 stream-map))
(plot-new-window? #t)
(define-values (*m* *k* *dt*) (values 1 10 0.01))
(define *v*
(stream-cons 0
(stream-map (lambda (v x)
(- v (* (/ *k* *m*) x *dt*))) *v* *x*)))
(define *x*
(stream-cons 1
(stream-map (lambda (x v)
(+ x (* v *dt*))) *x* (stream-rest *v*))))
(define *xs* (stream->list (stream-take *x* 500)))
(define *ts* (map (lambda (x) (* x *dt*)) (range 500)))
(plot (lines (map vector *ts* *xs*))
#:x-label "t" #:y-label "x" #:title "t-x")
ストリーム(遅延リスト)を実体化させる関数がstream->listだ。これで遅延リストだったストリームがフツーのリストへと変換される。「変換される」って簡単に言ったが、事実上、ここで僕らが遅延リストに仕込んだ「抽象的な計算式」に従って遅延リストの先頭から順繰りに計算を行って値を具現化してくれる。
stream-takeは遅延リストの先頭から指定しただけの要素数(あるいは長さ)の部分ストリームを返してくれる。返り値も当然遅延リストとなる。ここでは原作通りに500個の要素を引っこ抜いてこよう。
plotモジュールのlines関数は引数にx, yの組のベクタのリスト(つまり点の座標を表す)を取り、それらを線で結んでくれる描画関数だ。その結果をplotに渡すと無事グラフを描画してくれる。

単振動の運動方程式、と言う微分方程式の一般解の通り、三角関数のグラフが現れる(※2)。
さて、ここでRacketから離れてPythonに行こう。
何故に最初にRacketに行ったか、と言うとだ。何度も言ったが、漸化式はそのまま再帰でプログラミングするのが通常は良好だ。何故なら何も工夫が要らないから、だ。
ところがPythonは実はかなりヘナチョコで、再帰が苦手だ。そこで数学的な漸化式との親和性を取り敢えず語る為にRacketに寄り道した。
一方、このブログでは何度か指摘してるが、実は末尾再帰と言うのは人力で、機械的にwhile文へと変換出来る。
例えばPythonでは次のように書けるだろう。
m, k, dt = 1, 10, 0.01
def v_(n_max):
n = 0
v_n = 0
while True:
if n > n_max:
return v_n
v_n -= (k/m) * x_(n-1) * dt
n += 1
def x_(n_max):
n = 0
x_n = 1
while True:
if n > n_max:
return x_n
x_n += v_(n-1) * dt
n += 1
ところが、こいつも、関数x_に与える引数が小さい時には問題なく計算を行ってくれるが、件のページみたいに500を与えるといつまで経っても計算が終わらない、と言うようなハメに陥るんじゃないか(※3)。
Pythonが不得手な再帰で書かれてないのに?と不思議に思うかもしんない。そう、ここでも実は2つの関数が呼び出し合ってるので、相互再帰っぽい状態になってる事が1つ。そしてもう1つは、Racketでも見たように、どっちにせよ、「今の状態を計算する」には「多量の繰り返し計算を要する」事となり、しかも値が返されてしまえばその値は消えてしまい、nの値が増える度に加速度的に「繰り返し計算」が増えていくため、速い言語でないPythonは計算を終わらす事が出来なくなっちまうのだ。
これ、一体どーすんの、とか言う話になるだろう。
ところでその解決策の1つの話をする前に別の話をしよう。
上のサンプルコードはwhileを使って書いたが、ちとここで寄り道をしてみる。例によって高階関数reduceの話だ。
以前このブログでPythonのreduceを使った際には飛び道具的な使い方をした。
今回はちとオーソドックスな話をする。それは一体いつreduceを使うべきか、と言う指針の話だ。
要は、reduceを使うチャンス、と言うのは、
- 何らかの初期値があり、そしてリストの類があり、初期値に対して計算結果を足しまくったり、あるいは掛けまくったりの類のパターンがあった場合
だ。要するに累積器、accumulaterに初期値から続く計算結果を加工しまくる場合が、reduceの出処なんだ(※4)。
もう一回件のページに挙げられていた数式を見てみよう。

両者とも初期値v_0やx_0からはじまって上の数式を適用され続けてる。つまり初期値はそのうちv_nになって、v_(n+1)を算出する為にはアキュムレータになってるv_nをまた数式に従って加工せねばならない。事情はx_nに対しても全く同じだ。
こういう時がreduceの出番なんだ。
from functools import reduce
m, k, dt = 1, 10, 0.01
def v_(n_max):
return reduce(lambda v_n, n: v_n - (k/m) * x_(n-1) * dt, \
range(1, n_max+1), 0)
def x_(n_max):
return reduce(lambda x_n, n: x_n + v_(n) * dt, range(1, n_max+1), 1)
reduce初心者は、とにかくreduceと言う関数の異様さ、そしてlambdaと言う謎めいたキーワードに尻込みしてしまう。
ただし、lambda式の中身を見るとむしろ愚直に与えられた数式そのものを「プログラム」にそのまま変換してる事が分かるだろう。実は特にムズい事はしてないのだ。
そして数列上の「添字」であるnのパートはそのままリストとして考えれば良く、初期値も題意に沿ってそのまま、だ。
言い換えると、reduceやlambdaと言う表現を無視すれば、「そのまま素直に」数式が表現してるモノをそのままプログラミングに持ち込んでる、と言える。
さて、与題をreduceを使って書いてみた。殆どワンライナー化したvとxだが、上に挙げられてる「相互再帰的状態」と「繰り返しの多重呼び出し」が回避されたわけではない。相変わらずPythonの計算は遅くて終わらないだろう(ある意味whileの時より酷いかもしれない・笑)。
しょーがないんで、人力での最適化技法を導入する。そしてハッシュテーブル(辞書型)を使う事に尻込みしてる層に、ハッシュテーブルが何故に凄くて愛用されているのか、と言う実例を紹介しよう。
この、辞書型を利用した計算の最適化をメモ化(memoize)と呼ぶ(※5)。
上のRacketでの遅延リストを用いた計算が何故に関数より早く終わるのか、と言うと一々値を計算しなかったから、だ。「一回計算された値はいつでも参照出来る」お陰で、値を求めるには値を参照すれば良く、それが結果として計算の高速化に結びついている。
ここで行うメモ化、と言うアイディアも全く同じだ。「一回計算した値」を項数nをキーとしてハッシュテーブルに登録する事で、再計算の必要が生じた時にハッシュテーブルから高速に値を検索すれば良い、と言うのがその仕組み。
まずは大域変数を増やす。
m, k, dt, x_table, v_table = 1, 10, 0.01, {}, {}
xの値を登録するハッシュテーブルx_tableとvの値を登録するハッシュテーブルv_tableの2つを追加しよう。
そして関数を次のように書き換える。
def v_(n_max):
def foo(v_n, n):
try: v_n -= (k/m) * x_table[n-1] * dt
except KeyError:
x_table[n-1] = x_(n-1)
v_n -= (k/m) * x_table[n-1] * dt
finally: v_table[n] = v_n
return v_table[n]
return reduce(foo, range(1, n_max+1), 0)
def x_(n_max):
def foo(x_n, n):
try: x_n += v_table[n] * dt
except KeyError:
v_table[n] = v_(n)
x_n += v_table[n] * dt
finally: x_table[n] = x_n
return x_table[n]
return reduce(foo, range(1, n_max+1), 1)
以前のreduceを使ったヴァージョンはlambda式を使っていたが、こっちのヴァージョンではローカル関数fooを使って定義してる。そのせいで行数は増えてしまった。これも全てPythonのlambda式がヘナチョコだから、だ。Pythonのlambda式はLispやRubyと違って複数の式を取れないので、中に例外処理を取る事が出来ないんだ。
ここでローカル関数fooが行ってる事は
- ハッシュテーブルから必要な値を探し、式を計算する。
- ハッシュテーブルに必要な値が無かった場合は、関数を計算してその値をハッシュテーブルに登録する。そしてそれを利用して式を計算する。
- 1. と 2.、どっちの結果にせよ、ハッシュテーブルにnをキーとして今回の値を登録する。
- ハッシュテーブルからキーがnの値を返す
と言う事だ。ハッシュテーブルに値が無かった場合、keyErrorと言う例外を投げてよこすので、それをキャッチしつつ計算を継続し、ハッシュテーブルに新しいキーと値をセットするんだ。
この関数fooさえでっち上げればあとはreduceが計算を処理してくれる。
>>> x_(500)
-0.9929452110033562
>>>
あれだけPythonが苦労してた計算が一瞬で終わる。これも「繰り返しの再計算」を徹底して避けたお陰だ。このヴァージョンの場合、もう一度言うが、計算に必要な値は全部ハッシュテーブルに登録されて行くので、それを参照するだけで計算が行える(※6)。
なお、ハッシュテーブルを大域変数として定義したお陰で、vやxの計算後はハッシュテーブルに値が登録されてる事が確認出来る。

大域変数としてのハッシュテーブルに計算データが残ってる、と言う事は、それを利用してグラフをプロット出来る、と言う事でもある。
ではその「残りカス」(笑)も利用して、原作のようにグラフをプロットしてみよう。
全コードは次のようになる。
#!/usr/bin/env python3
import matplotlib.pyplot as plt
from functools import reduce
m, k, dt, x_table, v_table = 1, 10, 0.01, {}, {}
def v_(n_max):
def foo(v_n, n):
try: v_n -= (k/m) * x_table[n-1] * dt
except KeyError:
x_table[n-1] = x_(n-1)
v_n -= (k/m) * x_table[n-1] * dt
finally: v_table[n] = v_n
return v_table[n]
return reduce(foo, range(1, n_max+1), 0)
def x_(n_max):
def foo(x_n, n):
try: x_n += v_table[n] * dt
except KeyError:
v_table[n] = v_(n)
x_n += v_table[n] * dt
finally: x_table[n] = x_n
return x_table[n]
return reduce(foo, range(1, n_max+1), 1)
if __name__ == '__main__':
x_(500) # 出力せずにここで一回計算させただけでハッシュに値が登録される
t = [i * dt for i in x_table.keys()]
x = [i for i in x_table.values()]
plt.plot(t, x)
plt.savefig('t-x.png')
plt.show()
これを実行すれば、原作通りにmatplotlibと言う外部ライブラリ(※7)がグラフを描画してくれる。

と言うわけで、色々なテクニックを取り敢えず「試用」してみるには数学的スクリプトが良い材料になる、と実感して頂けただろうか。
実感して貰えれば幸いだ。実感して貰えなければ「実感しろ」と言いたい(強制・笑)。
※1: Racket組み込みのstream-mapは貧弱で、第二引数のストリーム(遅延リスト)は1個しか取れない。SRFI-41の「完全な」stream-mapを使うべきだ。
※2: ちなみにこのテの単振動の数学的な一般解は

になる。Cは積分定数で初期値が決める。これを微分すれば速度になり、再び微分すれば加速度になる、と言うのは高校で習う初歩的な微分に纏わる数学(これは物理ではなく、「運動学」と言う数学の範疇)だ。
※3: 恐らく、20台前半辺りまでは辛うじて計算してくれるが、30に近づくに連れて「計算が終わらなく」なるような事態になると思う。
そもそも、Pythonは、全てのプログラミング言語を合わせて見てみても、どっちかと言うと遅い部類のプログラミング言語だ。従って、実の事を言うと、最近の世間的な印象と違って計算量が多いAI向きではない。
何故、AI向けじゃないのにAI向けだ、と思われてるのか、と言うと外部ライブラリのお陰なのだが、ぶっちゃけて言うとそれらはPythonでは書かれていない。殆どがC言語で書かれている、と言うのがその実態だ。
つまり、事実上、PythonはC言語で書かれたプログラムを動かす為のユーザーインターフェースになっている。
※4: ちなみに、最近、Lispの真似をして高階関数的な機能を取り込んでるプログラミング言語では、reduceとかfoldと言う名前を捨て、機能的には累積器(accumulater)に値を累積(accumulate)するので、そのまんまaccumulateと言う名前にしてる例も出てきている(C++とか)。
実はPythonにもaccumulateがあり、機能的には全くreduceと同じだが、返り値がイテラブルとなってるのが違う。
※5: メモ化は実用Common Lisp(PAIP)の253ページ辺りに詳しい解説が載ってる。または、On Lispの第4章辺りを参考にしても良いだろう。
ちなみに、PAIPでは263ページにScheme的な遅延評価機構の説明を行っている。On Lispでは14章でそれを扱っている。
いずれにせよ、これらの「最適化技法」はLispでは割に当たり前のテクニックとなっている。
※6: なお、実のことを言うと、Pythonではメモ化を簡単に行えるようなデコレータが用意されてはいる。
ただし、Pythonのヴァージョンによって名前が変わっていたり、ハッシュテーブルの上限値が厳しかったり、最適化の自由度が低い、とか最適化が甘い、とか色々と嫌な思いをしたので(笑)、今回は完全にこの問題に最適化するようにプログラムした。
なお、今回のメモ化はこのブログでは恐らく初めて「大域的なデータテーブルに値を登録した」例であり、破壊的変更を進んで行った例でもある。
つまり、「メモ化」と言うのは関数型プログラミング技法ではなく、最適化の為の技術の例で、そういったケースで初めて「破壊的変更を止むなく行う」と言う事である。
これがまさしく伝家の宝刀で、毎回抜くわけにはイカんのだ。
※7: インストールしてない人は端末から
python3 -m pip install matplotlib
すれば簡単にインストール出来るだろう。
なお、こっちで試してみると、Python3.9以降はこの辺の外部ライブラリは軒並み全滅で、3.8が一番安定して「今までの資産が使える」ようになっている(2022/5/19現在)。
この互換性が度々途切れるのがPythonのアタマの痛いトコだ。














