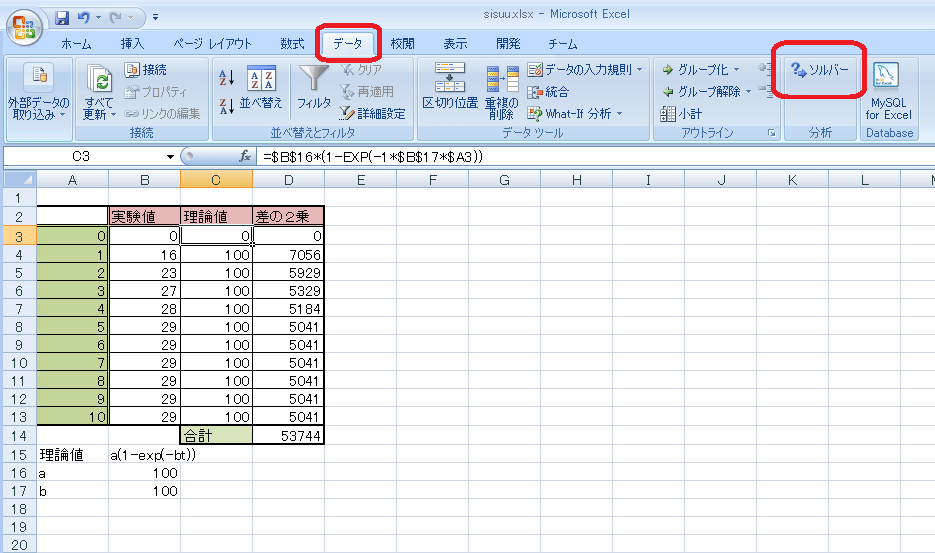
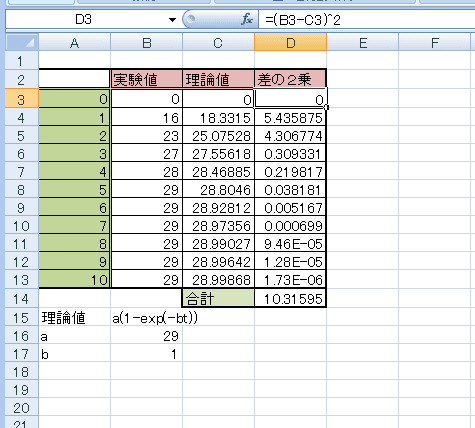
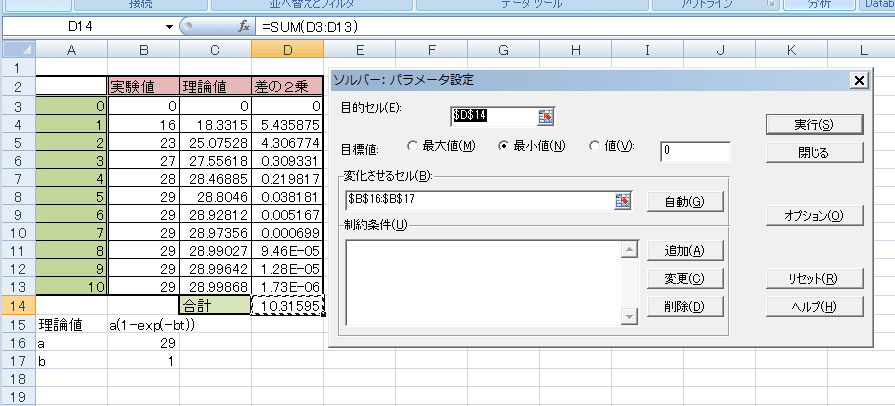
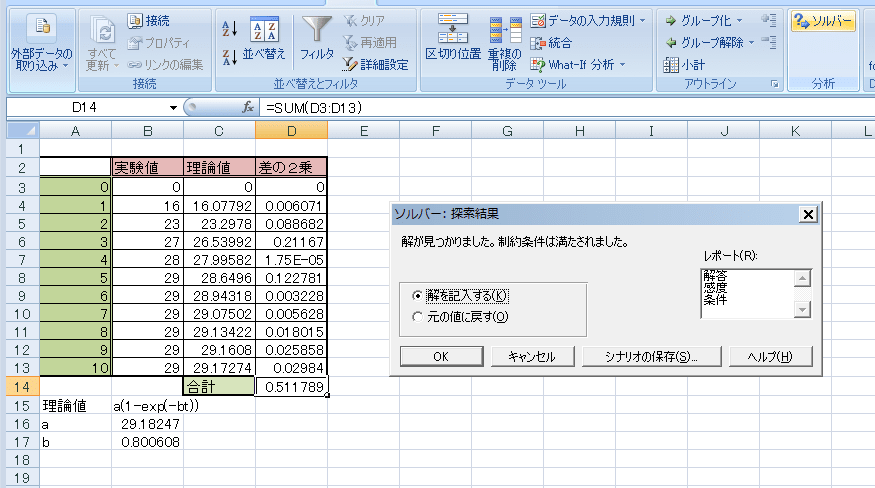
前に
テスト自動生成で考えるべきこと概論
http://blog.goo.ne.jp/xmldtp/e/a6aaf9ac55d4eced150bcb48ae7544d3
で、「各テストにおける自動生成について書こうと思った」と書いたけど、
その「単体テスト」版について、書いてみた。
【単体テストの種類】
単体テストと呼ばれるものには2種類ある
(1)ソースコードの中身に基づいて行うもの(ホワイトボックステスト)
ソースコード中の
命令すべてをテストする(命令網羅C0)
if,switch文のすべての分岐をテストする(分岐網羅C1)
分岐の組み合わせ条件すべてをテストする(条件網羅C2)
C0,C1は絶対100%、C2は建前100%?を目指してテストする
(2)ソースコードは見ないで、インターフェースをもとに行う(ブラックボックステスト)
メソッド(ないしは関数)の、引数やアクセスするDB、ファイルの値などを
変えて、仕様を満たしているか確認するもの
※ブラックボックステストは、ソースを見ないテストのこと。なので
単体テストだけでなく、結合、総合テストもブラックボックステストとなる。
(1)は、GDBなどを用いて、プログラム中の値をセットしてテストする。
ということは、もし、コンパイラのIF,SWITCH条件をもとに、命令・分岐・条件の
テストケースを作成し、そのテスト仕様書を生成、かつ実行するgdbのスクリプトを
自動生成することは、技術的に可能に思える。しかし、寡聞にして、そのような
ツールがあるとは聞かない。・・・なにか、理由があるのか?
とにかく、そんな感じで、今回の話題には取り上げないこととする。
以降(2)について、説明する。
【テスト対象】
(2)において、テスト対象となるのは、大きく以下の2つ。
(あ)メソッド(関数)の全引数の境界値テスト
(い)メソッドの返り値等、結果の同値テスト
(あ)について、
●引数の値を入れて調べる(値をいれないでnullで済む場合は、nullの場合も調べる)が、
そのとき、引数の取りうる値が、男・女など、固定の値の場合は、その値を調べればよいが
(異常系として、わざと、それ以外の値も調べるが)、整数、実数の場合、20以上とか、
ある値の前後で動作が異なる時がある。その場合、
整数値であれば、 その値ー1、その値、その値+1
を調べる。20以上だったら、19,20、21
実数の場合、その値は当然調べるが、その値より大きい値、小さい値を適当に調べておく
●返り値については、返り値がいくつかのグループ化ができる場合は、そのグループになる
テストケースを少なくとも1つは用意する。例えば、20歳以上は大人料金、20歳未満は
子供料金の場合は、大人料金、子供料金の両方のケースを調べる。
これは、一見、引数の境界値を調べれば、同値条件すべてが調べれられそうだが、
(そうなりこともあるが) 調べられないこともある。
たとえば、引数が会員NOで、関数内で会員DBを会員NOでアクセス、年齢を取得し、
その年齢をもとに大人料金、子供料金を決める場合、会員NOの境界値はないので、
大人料金のケース、子供料金のケースが、カバーされるとは限らない(例:すべて大人の
テストデータを作ってしまった場合)。この場合、DBのテストケース等を工夫して、
両方のケースができるようにする。
【テスト自動化】
・単体テストに限らず、自動化するときには、なんかものすごいツールをつくるというよりは、
ゴミプロとか、マクロで小さなプログラムを作って、使い捨てるぐらいの気持ちの方がいい。
プロジェクトによって、テスト中にDBのテストケースを操作しなくちゃいけなくなったりと、
いろいろなので、その場にあったプログラムを作り、あとは修正するより新規に作った方が
速い。
・単体テストで作るべきものは2つ
仕様書
JUnitテストスクリプト
これを、以下の入力から作る
メソッドの引数・返り値(これは関数・メソッドから抽出できる)
引数の境界値と返り値の同値(入力してもらう必要有)
そして、作業中に、予想されるテスト結果も入力する
・これを、以下の手順で作る
(a)メソッドの引数、型、境界値等の入力
(b)テストケースと結果の入力
(c)自動生成
以下、詳細に説明する
■(a)メソッドの引数、型、境界値等の入力
ExcelシートまたはCSVファイルに以下のように
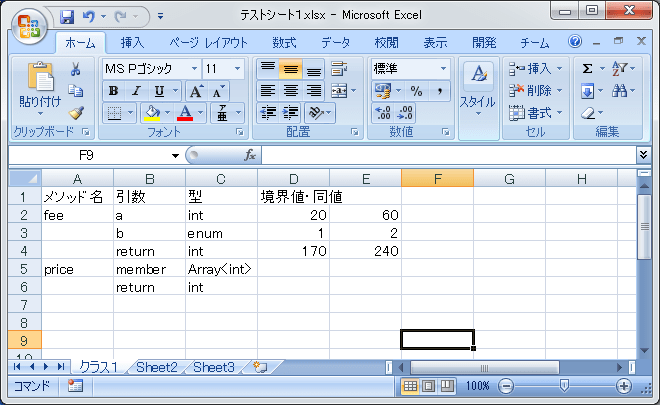
各クラスの各メソッドの引数ごとに1レコードとし、引数名、型、その引数の境界値・取り得る値を入力する
また、返り値がある場合、(引数名をreturnとしているもの)その型と、同値条件を書いておく
ここで、型がenumとあるのは、特定の値しか取り得ないときのもの
引数で何も書いていないのは、境界値がない(たとえば、y=ax+bのx,yのように、xとyの関係が1つ)
値で何も書いてないのは、値が1グループ(たとえば、y=ax+bのx,yのように、xとyの関係が1つ)
または、返り値なし(void)
ここから(b)を自動生成(ないしは人力生成)する
※ここまでの作業、手ですべて入れる必要はない。以下の手順で作業量は減る
・grepでソースファイルから、 publicやprivate等をふくむ行をとりだして
・そのうち、(をふくむ行を抽出し(これで、メソッド(型 引数・・・)の行抽出)
・各行に適当にタブと改行をいれて、CSVファイルを作って読み込ませてもOK
■(b)テストケースと結果の入力
自動生成した結果がこれ
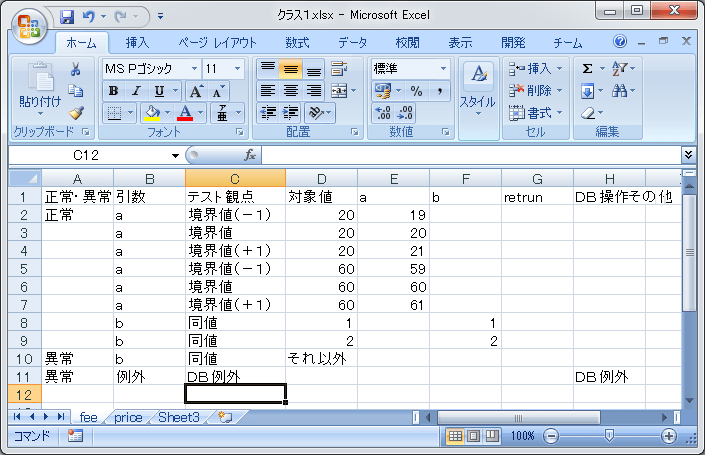
Excelの場合1シート1メソッド(CSVの場合1ファイル1メソッド)にしたほうが、作業はやりやすいはず
●(a)のシートの型と境界値に基づいて、各レコードを作成する
引数がintの場合、境界値があれば、境界値ー1、境界値、境界値+1のレコードを作成し、
境界値を「対象値」に
境界値+1等を「テスト観点」に
記入する。
引数がdouble,floatの場合、境界値があれば、境界値より小、境界値、境界値より大のレコードを作成、
引数がenumの場合は、enumのものと、「それ以外」というものを作成
引数が(Arrayや自分で作ったなどの)クラスの場合、nullと、値設定済みを作成
最後に例外ケースを作成する。
対象値のよこに引数を書いていく。その値を設定することになる。
自動設定時は、上記のように分かるところだけを埋めておき、あとは手作業で埋めることになる。
returnは、その引数を設定した場合、取り得る値を書くが、自動生成時はわからないので、空欄
手作業で埋める
その横にDB操作・その他とあるのは、引数を設定するだけではだめで、DB操作やフラグ操作などが
必要なもの。例外を出す時には必要なことが多いので、自動生成で例外の時にいれておいてもまあいい。
(今回は入れている)
●これで、手作業で値を埋めていく。こんなかんじ
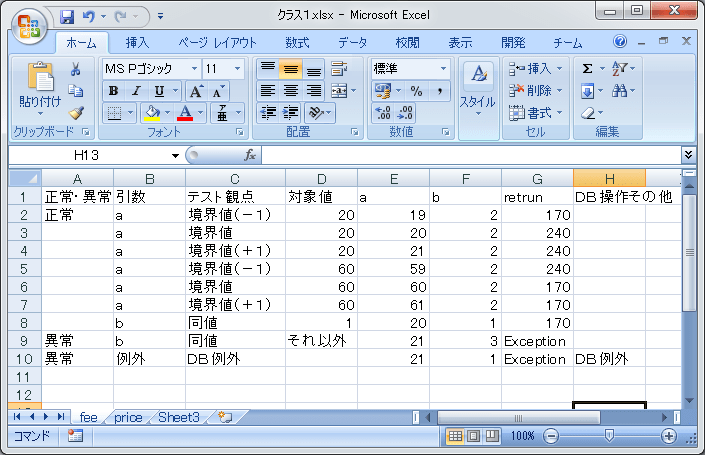
各引数(a,b)とreturnをすべて埋める。この段階で、テストケースを追加したほうがいい場合、
他のテストと一緒にやれるので、ケースを削除する場合がある。たとえば、bのフラグは、
会員(1)、非会員(2)で、
非会員の場合、20歳未満と60歳以上が170円、それ以外は240円
会員は何歳でも170円という規定になっているとすると、
境界値が関係するのは、非会員(b=2)の場合なので、2を設定している。
で、そうすると、b=2のケースは調べているので、そのケースを削除している
(b=1をあえて設定して調べている)
■(c)自動生成
ここから(c)を自動生成する。詳しい生成方法は、ケース(=プロジェクト)によって、
ドキュメント、スクリプトが違うだろうから省略する。
ただ、自動生成プログラムにこだわらくてよく、効率的なら、Excelのセルに適当な言葉を
いれて連結してもよい。
というか、小さい規模なら、上記のことを考慮に入れて、手作業でスクリプト、ドキュメントを
作った方が・・・はやいかな(^^;)
また、DBの冷害などを起こすところは、// DB例外 のようにコメントとして出力し、
手作業でコーディングしたほうが早いかもしれない(ただし、この場合、保守に注意)。
単体テストは、こんなかんじ。