QC7つ道具について(R言語を使って)をさらします.
1.QC7つ道具とは.
実は,下記の七つの道具を言います.
- 層別 Grouping (層別を抜いてグラフを入れる事もあり)
- ヒストグラム Histgram
- チェックシート Check sheet
- パレート図 Pareto chart
- 管理図 Control chart
- 散布図 Scatter Plot
- 特性要因図(魚の骨図)Cause-Effect chart (Ishikawa Diagram)
2.それぞれの内容
2-1.層別(層別を抜いてグラフを入れる事もあり)
層別とは,データを色々な要因(因子・Factor)で切り分け,調査するという概念です.
例えば,製造ロット毎,材料のロット毎,作業者毎,機械毎等,要因ごとに出来た製品のデータをグラフ化(ヒストグラムや管理図散布図等)してみたりして,比較し,どのような傾向があるかを調べます.
まあ,概念なので「道具」と呼ぶのはどうかとは思いますが,でも,QC7つ道具で一番強調されるのは,この「層別」です.
というか,この層別がわからないと,QC7つ道具は使えません.(品質管理の他の道具も使えません.)
層別を抜いてグラフを入れる教科書もあります.層別とはあくまで概念ですので,「道具」と呼ぶのはどうよ.という人もいるようです.そんな人はグラフを7つ道具に入れる事があるようですが,ヒストグラムもパレート図も管理図もグラフなのですから,それもあまりしっかりとした対応では無いような気がします.
それなら素直に,親和図法とか関連図(この2つは新QC7つ道具なのでダブルカウントですが)とか,品質機能(品質-代用特性)展開(データ・マトリクス展開と一寸違うので,ダブルカウントにはならないかも)とかを入れた方がいいような気がします.
宮川さんなどは,「対応ある推移図」(2つの時系列データを並べてグラフ化したもの)なんかは使い勝手があっていいよ.(宮川,品質を獲得する技術 タグチメソッドがもたらしたものP.49-50.)とか言っています.タイムラグがあるような変化には判りやすいかもしれません.
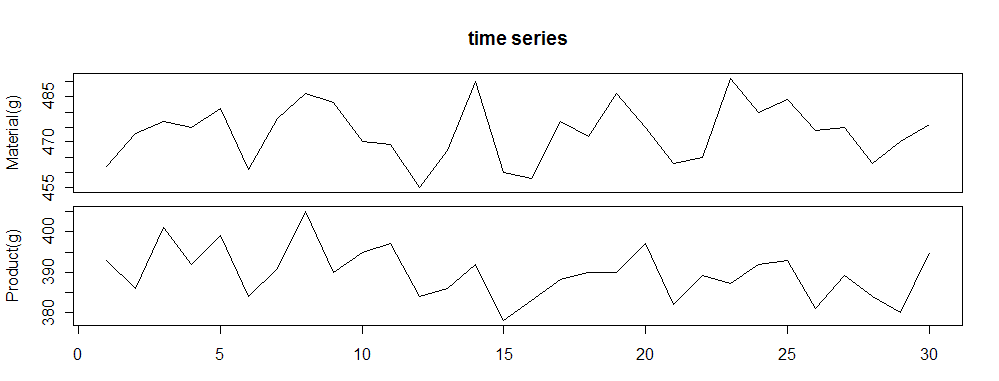
対応ある推移図 データは,2-6.散布図で使用したデータ.
2-2.ヒストグラム
ヒストグラムとは,測定等した値を階級毎に分け,その階級に当てはまるデータの個数をグラフ化したものです.
例えば,ある製品のSWの動作荷重を50g毎の階級にわけ,グラフ化したものが下記の図です.

図 SW動作荷重のヒストグラム
ヒストグラムでは,万遍なくバラツいているのか,偏っているのか等,データの傾向がわかります.
Rではこう作ります.
# まずデータをセット
sw.force<- c(
95,
105,105,105,
115,115,115,115,115,115,115,115,115,115,115,115,115,115,115,
125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,125,
135,135,135,135,135,135,135,135,135,135,135,135,135,135,135,135,135,135,135,135,135,
145,145,145,145,145,145,145,145,145,145,145,145,145,
155,155,155,155,155,155,155,
165,165,165,165,
175,175,175,
)
# その後ヒストグラムを作成
hist(sw.force,br="scott",main="SW Turn on Force(g)",xlab="SW Turn on Force(g)",ylab="Qty")
そう,Rでは1関数で出来るのです.凄い!
(ちなみにこのデータセットは値がそろってしまっていますが,これは,私が昔手書きで書いたグラフの値を目視で読んでいるからです.)
2-3.チェックシート
チェックシートとは,測定等した値を階級毎に分け,その階級に当てはまるデータの個数を数え上げるシートを指します.つまり,殆どヒストグラムと同じです.
ちなみに,教科書では4本縦線を引いて,最後にその4本の線を貫くように5本の線を引くように書いてありますが,これでは数え間違いが多く,(例えば5本縦線を引いて,6本目に横線を引いてしまうというように)この方法より,やはり漢字の国の人たちは,正の字で書いた方が間違いが少ないです.
2-4.パレート図
パレート図は,よく不良症状や原因の内容を表すのに使用します.
よく,「不良の約80%は,約20%の不良原因で起きている(これをパレートの法則と呼びます.)」とかいわれています.* この図を使うと,かなり実感できると思います.
そう,この図に特徴的なのは,累積構成比が線グラフになっている事です.これが斜め45度であれば,どの不良原因も同じように起きていますが,これが横に寝ていると,ある特定の不良原因が多く起きているということです.
また,改善前と改善後のパレート図を同じスケール(不良数(通常は縦軸)を同じ長さにする)に合わせて,改善効果を見るという使い方もしたりします.
*:ちなみに,これを提唱したのはJ.M.Juran博士です.ジュランさんは,どうやらパレートさん(この人はイタリアの経済学者で,「お金持ちは少数で,他の人たちは多数いる」つまり富は少数の人たちで占めているという事実を発見した人のようです.)の発見を知ったジュランさんは,不良や作業等にも同じ事がいえるのではないかと思いつき,調査した結果,やはり "vital few and trivial many"(重要な項目は少数で,そうではない項目は多数である) だった事を見つけ,これに「パレートの法則」と名付けました.(俗に言う8:2の法則というやつです.)
細かい話は,ジュランさんの自伝 "Architect of Quality" P.158にあります.

図SW不良のパレート図
Rではこうします.
# "qcc" パッケージの読み出し.
# ちなみに"qcc"パッケージをインストールしていない場合は,
#「パッケージ」-「パッケージのインストール」でqccを入れてください.
# パッケージのサイトからのダウンロードとインストールはRが自動的に
# してくれます
# その前に「CRANミラーサイトの選択」をやっておかないと,遠いサイト
# からのダウンロードになってしまうので注意.
library("qcc")
# まず,データセット
sw.defect<- c(7,1,1,2)
names(sw.defect)<- c(
"Bridge Solder",
"Part Remove out",
"Volume Broken",
"Pattern Detach"
)
# パレート図作成
pareto.chart(sw.defect,
ylab = "Def. Qty",
col=rainbow(length(sw.defect)),
las=2)
一寸残念なのは,この関数では「その他」項目が表示できないことです.
(なぜかデータをソートしてしまう)
荒木先生がRcmdrを使って「その他」が出るように改造したソフトがありますので,こちらを使用した方がいいかもしれません.
ここにあります(QC7tools)
2-5.管理図(シューハートのコントロールチャート)
工程が安定しているかどうかを判断する図です.製品や部品の寸法や温度等連続的な値を測定し,打点していきます.特徴的なのは,中心線と2本の外側の線(この線を「管理限界 Control limit」と呼びます.)があることです.*
このブログにしつこい位書いてありますが,中心線の上側や下側に点が固まっていたり,連続的に上側にいったり下側にいったりするような「トレンドが無く」,(つまり「連」が無い状態)管理線を越えて点がない場合,(まあ,1~2点ぐらいは見逃してあげるのが人情というやつですw.)その工程は「管理されている」という事になります.
*: ちなみに,この管理図を開発した人は,近代品質管理(統計的品質管理)の父Shewhart博士で,Deming博士の師でありかつ親友であった人です.
管理図には,x-R管理図,x-s管理図,np管理図,p管理図等色々ありますが,x-R管理図,np管理図辺りを覚えておけばOKでしょう.
ちなみにQCのことわざでは,"目標はまずR退治から" by 石川馨先生 だそうです.(宮川, 品質を獲得する技術 タグチメソッドがもたらしたもの, P50.参照)
一例として,x-R管理図をさらします.
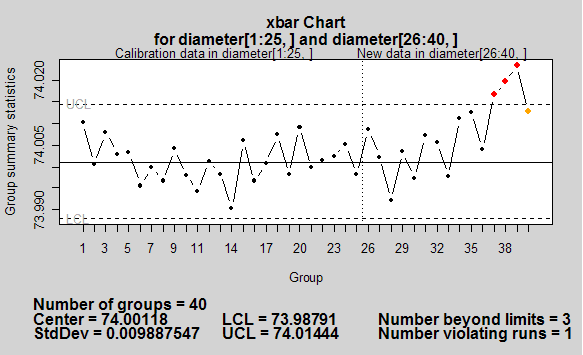
xバー管理図

R管理図
Rではこうします.
# "qcc" パッケージの読み出し.
# 一回呼べばOKですので,前のパレート図の時に呼んだ場合は必要ないです.
library("qcc")
# データセット "pistonrings"の呼び出し.ちなみにこのデータセットは
# ピストンリングの直径を測定したデータです.単位はmm.
data(pistonrings)
# データセットの処理.
attach(pistonrings)
diameter <- qcc.groups(diameter, sample)
diameter
# "xbar" 管理図の作図.
qcc(data=diameter[1:25,], type="xbar", newdata=diameter[26:40,])
# R管理図の作図.
qcc(data=diameter[1:25,], type="R", newdata=diameter[26:40,])
# 後処理.
detach(pistonrings)
2-6.散布図
散布図とは,Aという項目とBという項目を対にしてデータを取り,そのデータを方眼紙に点としてプロットしたものです.
普通は,入力-出力を対にしてデータを取ります.
ここでは,教科書「新版 品質管理のための統計的方法入門」P.161 のデータを使用します.
データは,パンを焼く前(生地:横軸)の重さと焼き上がりの重さ(製品:縦軸)(共にg)のデータです.

散布図
Rではこうします.
# まずデータセット.データはm:生地,p:パンです.
m<- c(462,473,477,475,481,461,478,486,483,470,469,455,467,490,460,
458,477,472,486,475,463,465,491,480,484,474,475,463,470,476)
p<- c(393,386,401,392,399,384,391,405,390,395,397,384,386,392,378,
383,388,390,390,397,382,389,387,392,393,381,389,384,380,395)
# データをデータフレームに展開
bread<- data.frame(material= m, product= p)
bread
# 生地をヒストグラムで確認
hist(bread$material,br="scott",main="Bread Materials",xlab="Material(g)")
# パンをヒストグラムで確認
hist(bread$product,br="scott",main="Bread Products",xlab="Product(g)")
# ボックス・プロットで両方いっぺんに比較(一番目が生地,二番目がパン)
bread.bp<- boxplot(bread$material,bread$product)
bxp(bread.bp,show.names= TRUE,main="Bread Material and Product(g)")
rug(jitter(bread$material),side= 2)
rug(jitter(bread$product),side= 4)
# 散布図を作成
plot(bread$material,bread$product,
xlab= "Bread materials weight (g)",
ylab= "Bread products weight (g)",
main= "Bread Material and Product(g)",
)
# フィットする直線を書く
bread.lm<- lm(bread$product ~ bread$material) # 直線回帰線
abline(bread.lm)
# 相関係数の計算(準備)
(Sxy<- sum((bread$material-mean(bread$material))
*(bread$product-mean(bread$product)))) # xy平方和
(Sxx<- sum((bread$material-mean(bread$material))^2)) # x平方和
(Syy<- sum((bread$product-mean(bread$product))^2)) # y平方和
# correlation coefficient
Sxy/(sqrt(Sxx*Syy)) # 計算で出すとこうなる.
cor(bread$material,bread$product) # Rの関数はこう.(やはり楽)
# 回帰分析結果
summary(bread.lm)
2-7.特性要因図
特性要因図とは,特性(出力)と要因(因子:Factor)との関係を表した図で,その形状から魚の骨図とも呼ばれます.ちなみに,この図法を考案した石川馨博士にちなんでIshikawa Diagramとも呼ばれたりします.
要因の大骨にはよく,Man(作業者),Machine(機械),Material(材料),Method(方法)の4Mを良くあげますが,分析の内容によっては,これにこだわる事は無いでしょう.また,樹形図でも,トポロジー的には同じなので,これで代用してもいいと思います.(私もワープロとかでは書きづらいので,樹形図を使う事が殆どです.)
Rにもこの機能がありますが,中骨までしか書けないので,あまり役に立ちません.
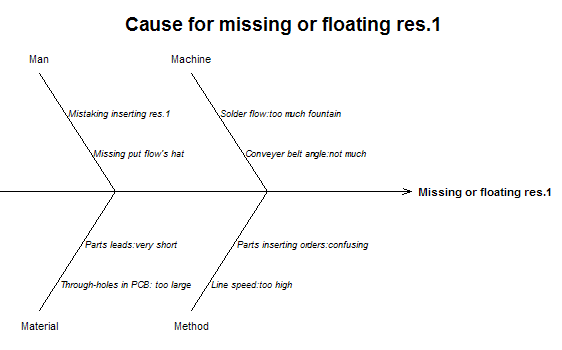
特性要因図
参考までに,Rではこうします.
# "qcc" パッケージの読み出し.
# 一回呼べばOKですので,前のパレート図や管理図の時に呼んだ場合は必要ないです.
library("qcc")
# 特性要因図の中身を定義する
cause<- list(
Man= c(
"Mistaking inserting res.1",
"Missing put flow's hat",
),
Machine= c(
"Solder flow:too much fountain",
"Conveyer belt angle:not much"
),
Material= c(
"Through-holes in PCB: too large",
"Parts leads:very short"
),
Method= c(
"Line speed:too high",
"Parts inserting orders:confusing",
)
)
effect<- "Missing or floating res.1"
# 特性要因図を作図
cause.and.effect(cause,
effect,
title= "Cause for missing or floating res.1",
cex= c(0.7,0.6,0.7)
)
3.参考文献
- Juran, Joseph M., Architect of Quality, 2004, ISBN:0-07-142610-8
- 荒木孝治 他, フリーソフトウェアRによる 統計的品質管理入門, 2005,ISBN:4-8171-9148-1
- 鐵建治, 新版 品質管理のための統計的方法入門, 2000, ISBN 4-8171-0342-6
- 宮川雅巳, 品質を獲得する技術 タグチメソッドがもたらしたもの, 2000, ISBN:4-8171-0399-6
- 船尾暢男, The R Tips データ解析環境Rの基本技・グラフィック活用集, 2005, ISBN:4-86167-039-X
- Crawley, Michel, J, Statistics An Introduction using R, 2005,ISBN:0-470-02298-1
- Scrucca, Luca, "qcc" help (in R language package "qcc")
- R Development Core Team, R: A language and environment for statistical computing.(Ver. 2.2.1), 2005, ISBN:3-900051-07-0
>








